نحوهی کار Vision Transformer (ViT)
- دسته:اخبار علمی
- هما کاشفی
مدل ViT (Vision transformer) یک مدل شبیه به transformer است که برای انجام تسکهای پردازش بینایی طراحی شده است. در این مقاله می آموزیم که این مدل چگونه کار میکند.
مقدمه
مدل ViT به عنوان جایگزین رقیب شبکههای عصبی کانولوشنی (CNN) بوجود آمد. در حال حاضر CNNها را میتوان پیشرفتهترین مدلها در حوزهی بینایی ماشین دانست که به طور گستردهای در تسکهای مختلف شناسایی تصویر استفاده میشوند. مدلهای ViT از نظر کارایی و دقت محاسباتی تقریباً چهار برابر بهتر از CNNهای پیشرفتهی فعلی عمل میکنند.
هرچند شبکههای عصبی کانولوشنی سالها در حوزهی بینایی ماشین، حرف اول را میزدند اما مدلهای جدید ViT قابلیتهای قابل توجهی از خود نشان دادهاند. ViT ها در نهایت در بسیاری از تسکهای بینایی ماشین به عملکرد بهتری نسبت به CNNها دست یافتهاند.

Vision Transformer (ViT) چیست؟
مدل Vision Transformer (ViT) در سال 2021 در یک مقالهی پژوهشی کنفرانسی با عنوان “An image is Worth 16*16 Words: Transformers for Image Recognition at Scale” معرفی شد. این مقاله در ICLR 2021 به چاپ رسید. کد fine-tuning و مدلهای ViT پیش آموزش دیده در گیت هاب Google Research در دسترس هستند. مدلهای ViT روی دیتاستهای ImageNet و ImageNet-21k پیش آموزش دیدهاند.
ViTها کاربردهای گستردهای در تسکهای رایج تصویر مانند شناسایی اشیا، سگمنت بندی تصویر، کلاسبندی تصویر و تشخیص عمل دارند. علاوه بر این ViTها در تسکهای مدلسازی مولد و چند مدلی نیز استفاده میشوند. مانند زمینه سازی بصری، پاسخگویی به سوالات بصری و … .
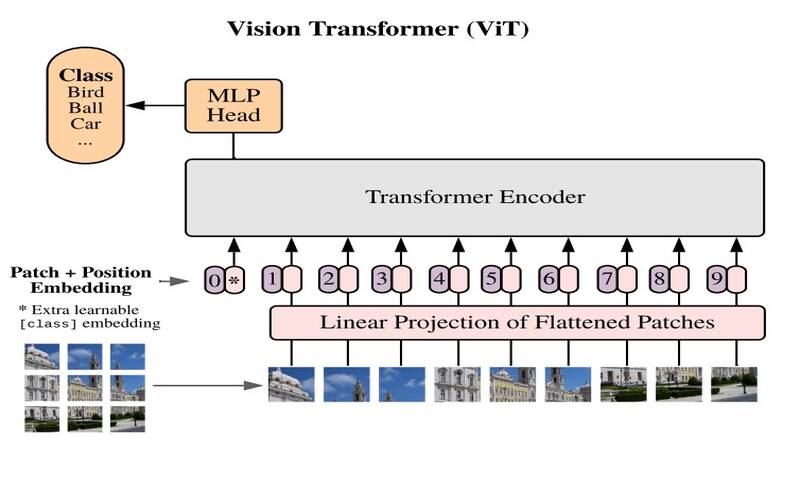
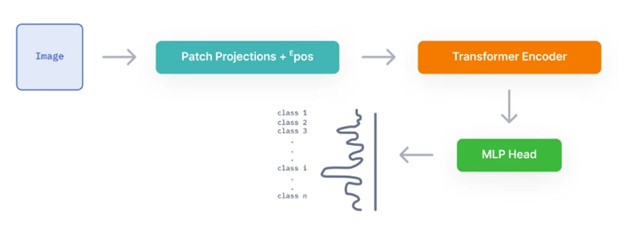
در ViTها، تصاویر به صورت توالی نشان داده میشوند و برچسبهای کلاس برای تصویر پیش بینی میشوند. در نهایت به مدل امکانی را میدهند تا ساختار تصویر را به طور مستقل یاد بگیرد. تصاویر ورودی به عنوان توالی از patchها در نظر گرفته میشوند که هر patch با ادغام کانالهای تمام پیکسلها در patch به یک بردار منحصربفرد تبدیل میشود. سپس به صورت خطی به ابعاد ورودی موردنظر، تصویر میشود.
معماری vision transformer به صورت مرحله به مرحله به شکل زیر است:
1-تصویر به patchها تقسیم میشود
2-همهی patchها flat میشوند
3-embeddingهای خطی با ابعاد پایین تر از patchها تولید میشود
4-positional embedding اضافه میشود
5-توالی به عنوان یک ورودی به انکدر ترنسفورمر استاندارد داده میشود
6-مدل با برچسبهای تصویر آموزش داده میشود
7-مراحل fine-tuning برای کلاسبندی تصاویر انجام میشود
Patchهای تصویر، توکنهای توالی (مانند کلمات) هستند. بلوک انکدر مشابه مدل ترنسفورمر اصلی است که توسط Vaswani et al (2017) معرفی شده است.
چندین بلوک در انکدر ViT وجود دارند که هر بلوک شامل سه عنصر پردازشی اصلی است:
Layer Norm
Multi-head Attention Network (MSP)
Multi Layer Perceptron (MLP)
لایهی اول Layer Norm روند آموزش را در مسیر خود نگاه میدارد و به مدل قابلیتی میدهد تا با تغییرات موجود در تصاویر آموزشی، سازگاری پیدا کند.
Multi-head Attention Network (MSP) شبکهای مسئول تولید نگاشتهای attention از توکنهای بصری است. این نگاشتها به شبکه کمک میکنند تا روی مهمترین و بحرانیترین نواحی تصویر مانند اشیا تمرکز کنند. مفهوم attention map شبیه به مفهومی است که در ادبیات بینایی ماشین نیز دیده میشود (مانند saliency map و alpha-matting).
MLP یک شبکه کلاسبندی دو لایه با GELU (Gaussian Error Linear Unit) است. بلوک نهایی MLP همچنین MLP Head نامیده میشود و به عنوان خروجی ترنسفورمر استفاده میشود. در نهایت استفاده از یک لایهی softmax، برچسبهای کلاس هر تصویر را ارائه میدهد (به عنوان مثال اگر کاربرد مورد نظر، کلاسبندی تصویر باشد).
ViT چطور کار میکند؟
قبل از اینکه به طور دقیق بررسی کنیم که Vision Transformer چطور کار میکند، ابتدا باید اصول مفاهیم attention و multi-head attention که در مقالهی اصلی Transformer آمده را درک کنیم.
ترنسفورمر مدلی است که در مقالهی “Attention Is All You Need (Vaswani et al. , 2017) معرفی شد. مدلی است که از مکانیزیمی به نام self-attention استفاده میکند. این مکانیزیم نه CNN است و نه LSTM اما باعث میشود مدل ترنسفورمر از مدلهای موجود به طور قابل توجهی بهتر عمل کند.
توجه داشته باشید که بخشی که با عنوان Multi-Head Attention در شکل زیر مشخص شده، بخش اصلی ترنسفورمر است. اما از skip connectionهایی مانند شبکه ResNet نیز استفاده میکند.
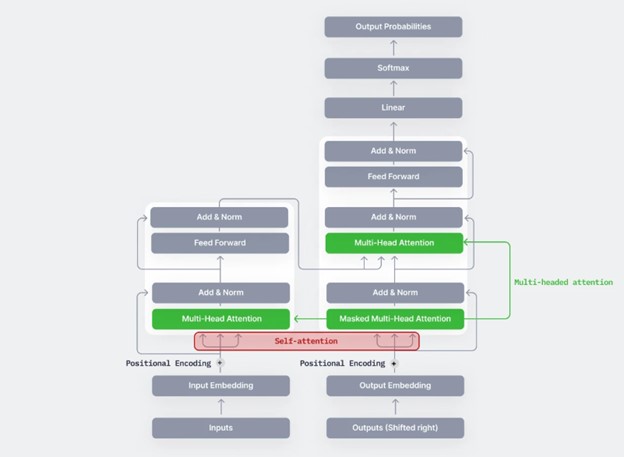
مکانیزیم attention که در مدل ترنسفورمر استفاده شده است سه متغیر دارد: Q (Query)، K(Key) و V(Value). به زبان ساده، این مکانیزیم، وزنهای attention یک توکن Query (توکن چیزی شبیه به کلمه است) و Key را محاسبه میکند و آن را در مقدار یا Value هر توکن ضرب میکند. به طور خلاصه ارتباط بین Query, Key را محاسبه میکند و آن در مقدار یا Value هر توکن ضرب میکند.
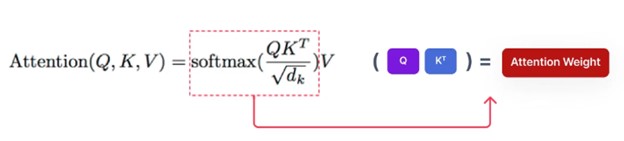
اگر محاسبات مربوط به Q, K و V را به عنوان single-head attention در نظر بگیریم، مکانیزیم multi-head attention به صورت زیر تعریف میشود. مکانیزیم single head در تصویر فوق از Q, K استفاده میکند. همچنان در مکانیزیم multi-head attention هر سر (Head) ماتریس تصویرسازی (projection matrix) مخصوص خود را دارد WiQ , WiK , WiV و وزنهای attention با استفاده از مقادیر ویژگی تصویر شده با این سه ماتریس محاسبه میشوند.
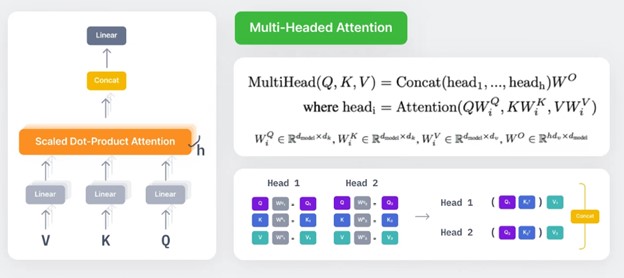
اگر بخواهیم مفهوم multi-head attention را به صورت شهودی درک کنیم میتوانیم بگوییم به ما امکانی میدهد که هر بار به طور متفاوتی به بخشهای مختلف توالی توجه کنیم. این بدان معنی است که:
از آنجاییکه هر head یا سر به بخشهای متفاوتی از ورودی، توجه میکند میتواند به اطلاعات موقعیتی بهتری دست یابد. ترکیب این اطلاعات موقعیتی که از هر head بدست میآید در نهایت ترکیب قویتری از اطلاعات را در اختیار ما قرار خواهد داد.
هر head با بدست آوردن همبستگی متفاوت و منحصر به فردی از کلمات، اطلاعات زمینهای متفاوتی را بدست خواهد آورد.
مدل Vision Transformer (ViT) مدلی است که از ترنسفورمر برای تسکهای کلاسبندی تصاویر بهره گرفته است. این مدل در اکتبر 2020 برای اولین بار معرفی شد (Dosovitskiy et al. 2020). معماری مدل تقریباً مشابه ترنسفورمر است با این تفاوت که امکانی فراهم میآورد که تصاویر را به عنوان ورودی پردازش کند.
این مقاله از بخش انکدر ترنسفورمر به عنوان مدل پایه برای استخراج ویژگی از تصاویر استفاده میکند. در مرحله بعد این ویژگیهای «پردازش شده» را به یک مدل MLP به عنوان ورودی میدهد تا کلاسبندی تصاویر را انجام دهد.
در حال حاضر، مدلهای ترنسفورمر محاسبات سنگین و پیچیدگیهای قابل توجهی دارند. به خصوص زمانی که میخواهند ماتریس attention را محاسبه کنند و این میزان محاسبات و پیچیدگی با افزایش طول توالی بدتر خواهد شد.
برای یک تصویر 28*28 دیتاست MNIST، اگر آن را به 784 پیکسل مسطح کنیم، باز هم باید با ماتریس attention به ابعاد 784*784 سروکار داشته باشیم تا ببینیم پیکسلها چطور با هم در ارتباطند. این میزان محاسبات حتی برای سخت افزارهای امروزی بسیار پرهزینه است.
از این رو، مقاله پیشنهاد میکند که تصاویر را به patch (تکههای) مربعی به شکلی از Attention سبک وزن «پنجرهدار» تقسیم کنید تا این مشکل برطرف شود.
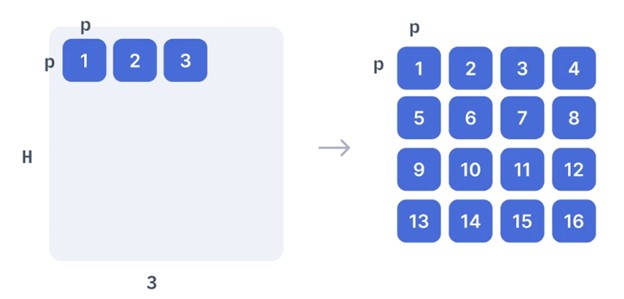
تصویر به patchهای مربعی تقسیم میشود.
این بخشها مسطح شده و به یک لایهی Feed Forward ارسال میشوند تا تصویر خطی patch بدست آید. این لایهی Feed Forward شامل ماتریس embedding E است که در مقاله ذکر شده است. این ماتریس E به صورت تصادفی تولید میشود.

برای تسهیل بخش کلاسبندی، نویسندگان از مقالهی اصلی BERT الهام گرفتهاند و یک embedding قابل یادگیری به هر تصویر patch ادغام کردهاند.
با این همه، هنوز هم ترنسفورمرها مشکل بزرگ دیگری دارند که ترتیب توالی در آن به طور طبیعی اعمال نمیشود. زیرا دادهها به جای آنکه با گامهای زمانی خاص ارسال شوند (مانند آن چیزی که در RNNها و LSTMها اتفاق میافتد) به یکباره ارسال میشوند و ترتیب توالی در آن مشخص نیست. برای حل این مشکل، مقالهی ترنسفورمر اصلی استفاده از Positional Encoding/Embedding را پیشنهاد میکند. این بخش، ترتیب خاصی در توالی ورودی ایجاد میکند.
ماتریس positional embedding به طور تصادفی تولید شده و به ماتریس ادغامی حاوی class embedding و patch projectionها اضافه میشود.
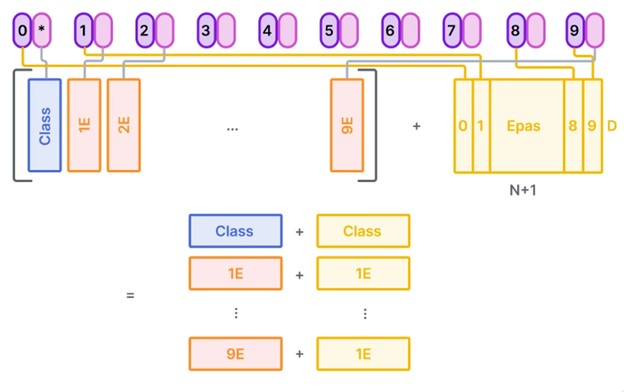
D سایز ثابت latent vector است که در سرتاسر ترنسفورمر استفاده میشود.
در نهایت این patch projectionها و positional embeddingها یک ماتریس بزرگتر میسازند. و به Transformer Encoder به عنوان ورودی داده میشود.
خروجی انکدر به یک پرسپترون چندلایه داده میشود تا تسک کلاسبندی تصویر را انجام دهد. ویژگیهای ورودی، ماهیت تصویر را به خوبی مشخص میکنند و عمل کلاسبندی MLP را بسیار سادهتر میکنند.
دوره های مرتبط

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین

پردازش تصویر(فصل اول): مباحث مقدماتی،آستانه گذاری تصویر،تبدیلات شدت روشنایی و هندسی
پردازش تصویر(فصل دوم): پردازش هیستوگرام تصویر

بسیار مقاله خوب و مفیدی بود. لطفا منابع مقاله روهم قراربدین. با سپاس
درود بر شما
خوشحالیم که مفید بوده. منابع مقالات هم طبق فرمایش شما اضافه شد.
با سپاس