شناسایی الگو






روشهای یادگیری جمعی ensemble learning-کد متلب و پایتون
قدرت در اتحاد است، اما اتحادی هدفمند و ساختار یافته! فلسفه اصلی یادگیری جمعی این است که به جای اتکا به یک مدل منفرد، چندین مدل در کنار هم برای حل یک مسئله به کار گرفته شوند. این رویکرد با…
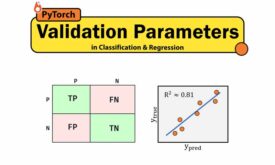
پارامترهای ارزیابی در مسائل رگرسیون و طبقه بندی
در طراحی و تعیین پارامترهای یک مدل یادگیری ماشین، روشها و پارامترهای ارزیابی نقش بسیار مهمی دارند. چرا که به ما کمک میکنند دید درستی به مدل طراحی شده داشته باشیم و متوجه بشویم که مدل یادگیری ماشین underfit ،overfit…
روشهای تشخیص دادههای پرت – Outliers
داده های پرت یا Outlier ها می توانند درکی از داده های مورد مطالعه به ما بدهند و بر نتایج آماری تاثیر بگذارند. شناسایی آن ها به ما کمک می کند تا ناهماهنگی را پیدا کنیم و هرگونه خطا در…
توضیح رویکرد ماشین بردار پشتیبان به زبان ساده
ماشین بردار پشتیبان(support vector machine) یکی از معروفترین الگوریتمهای یادگیری ماشین در مسائل طبقه بندی و البته رگرسیون هست. SVM به خاطر رویکرد منحصر به فردی که دارد باعث شده هم در مسائل طبقه بندی و هم در مسائل رگرسیون…
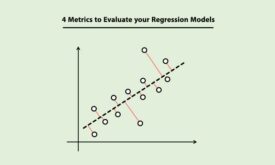
4 معیار مناسب برای ارزیابی مدلها در مسائل رگرسیون
رگرسیون یکی از رایجترین مسائل یادگیری ماشین هست که در آن خروجی مقادیر پیوسته و نامحدود هست. همانند مسائل طبقه بندی، در مسائل رگرسیون نیز نیاز به معیارهای ارزیابی هستیم تا بتوانیم عملکرد مدلهای رگرسیون را بررسی کنیم. در این…
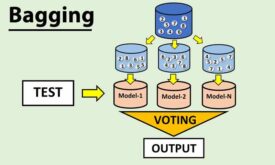
تکنیک bagging در یادگیری جمعی
تکنیک بگینگ-bagging که با نام bootstrap aggregating هم شناخته می شود، یک تکنیک یادگیری جمعی هست که برای حداقل کردن واریانس مدل استفاده می شود. در تکنیک bagging برای آموزش هر مدل، یک بخشی از داده به صورت تصادفی انتخاب…
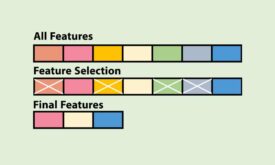
انتخاب ویژگی در شناسایی الگو
در شناسایی الگو و یادگیری ماشین، انتخاب ویژگی به فرایندی گفته می شود که در آن بهترین ویژگی ها از بین ویژگیهای استخراج شده انتخاب می شوند. با انتخاب ویژگی تعداد ویژگی ها به طور هدفمند کاهش پیدا میکنند تا…
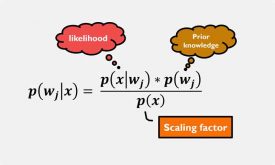
طبقه بند بیزین
طبقه بند بیزین یک روش آماری قوی هست که از تئوری بیزین برای دسته بندی الگوها استفاده میکند. تئوری بیزین یک روش آماری کمی هست که براساس حداقل کردن هزینههای تصمیم گیریهای مختلف کار میکند. در این مقاله میخواهیم به…
چرا ماشین بردار پشتیبان (SVM) در بین طبقهبندها جزء بهترینا هست؟
ماشین بردار پشتیبان(svm) یکی از معروفترین الگوریتمها در مسائل طبقهبندی هست که برای اولین بار توسط آقای Vladimir Vapnik در سال 1995 با عنوان support vectors networks مطرح شد. SVM در ابتدا برای مسائل طبقهبندی دو کلاسه خطی مطرح شده…
چطور با داده نامتعادل در آموزش مدلهای یادگیری ماشین مقابله کنیم؟
وقتی یک دادهای دارید که تعداد نمونههای گروهها خیلی متفاوت هستند، یا به اصطلاح یک داده نامتعادل دارید، دقت کلاسبندی به تنهایی به هیچ عنوان نمیتواند پارامتر مناسبی برای ارزیابی باشد. در این حالت بهترین کار اینه که سایر پارامترهای…
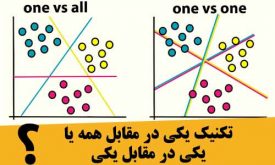
تفاوت تکنیک یکی در مقابل همه با تکنیک یکی در مقابل یکی
برخی از طبقهبندهای یادگیری ماشین، مثل SVM برای مسائل دو کلاسه طراحی شدهاند و اگر یکی بخواهد از این الگوریتمها در مسائل چند کلاسه استفاده کند، مجبور است که با کمک تـکنیکهایی طبقهبند را برای مسائل چندکلاسه تعمیم دهد. تکنیک…
انتخاب مدل یادگیری ماشین مناسب با کمک تیغ اوکام
احتمالا تا الان براتون پیش اومده که در یک پروژهای از دو مدل یادگیری ماشین استفاده کردهاید و مشاهده کردید هر دو تقریبا مثل هم عمل میکنند و بعد در انتخاب بین دو مدل به مشکل خوردهاید یا براتون سوال…