یادگیری ماشین




7 راه موثر برای جلوگیری از overfitting در الگوریتمهای یادگیری ماشین
وقتی یک مدل یادگیری ماشین عملکرد خیلی خوبی روی داده آموزشی داشته باشد ولی روی داده جدید عملکرد خیلی پایینی داشته باشد، در این صورت به احتمال بسیار زیاد overfitting رخ داده است. در این مقاله میخواهیم در ابتدا با…
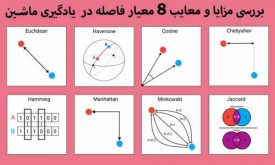
مزایا و معایب 8 معیار فاصله در داده کاوی و یادگیری ماشین
بسیاری از الگوریتمهای نظارت شده و غیرنظارتی، از معیارهای فاصله در پروسه یادگیری استفاده میکنند. برای مثال معیارهایی از قبیل فاصله اقلیدسی در الگوریتمهایی مثل knn, kmeans زیاد استفاده میشود. درک اینکه از کدام معیار فاصله در الگوریتمها استفاده کنیم…
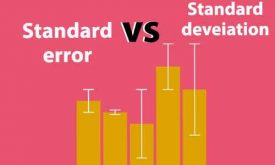
فرق بین انحراف معیار(standard deviation) و خطای استاندارد(standard error)
انحراف معیار(standard deviation) و خطای استاندارد(standard error) هر دو معیاری از پراکندگی هستند. انحراف معیار پراکندگی نمونهها حول میانگین را مشخص میکند. در حالی خطای استاندارد میزان انحراف میانگینهای تخمین زده شده از زیرمجموعههای یک جمعیت را مشخص میکند. در…
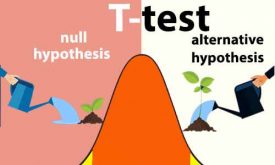
تست آماری ttest و مفهوم p-value
تست آماری ttest یک روش انتخاب ویژگی است که برپایه یک فرضیه آماری به ویژگیها براساس تفکیکپذیری آنها یک pvalue اختصاص میدهد و سپس براساس مقدار pvalueها، ویژگیهای مناسب را انتخاب میکند. میخواهیم در این بخش روش آماری ttest و همچنین…
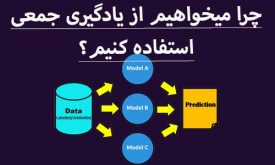
چرا میخواهیم از یادگیری جمعی(ensemble learning ) استفاده کنیم؟
یادگیری جمعی(ensemble learning) در حوزه یادگیری ماشین شامل تکنیکهایی هست که در آن برای حل یک مسئله، به جای استفاده از یک ماشین، از چندین ماشین به طور همزمان استفاده میکنند. در این بخش میخواهیم بررسی کنیم که چرا میخواهیم…
فرق بین feature mapping و انتخاب ویژگی (feature selection)
در یک سیستم شناسایی الگو برای کاهش بعد ویژگیها از دو رویکردِ نگاشت ویژگی ( feature mapping ) و انتخاب ویژگی(feature selection) میتوان استفاده کرد، هر دو روش سعی بر کاهش بهینه تعداد ویژگیها دارند، منتهی رویکرد هر کدام متفاوت…
چرا کاهش بعد (feature conditioning ) در پروژه های شناسایی الگو امکانپذیر است؟
در یک سیستم شناسایی الگو، کاهش بعد در مرحله چهارم بین طبقهبندی و استخراج ویژگی قرار میگیرید و هدفش کاهش تعداد ویژگی های استخراج شده میباشد تا کار تصمیم گیری را برای طبقهبند تسهیل کند. در این بخش میخواهیم این…
استخراج ویژگی در شناسایی الگو
ویژگی یک پارامتر یا خصیصه قابل اندازه گیری از پدیدهای هست که مشاهده میکنیم. ویژگی مشخصات مهم یک پدیده(object) را کمّی میکند. به فرایند اندازهگیری این پارامترها استخراج ویژگی گفته میشود. بخش استخراج ویژگی در همان ابتدای یک سیستم شناسایی…
شناسایی الگو چیست؟
شناسایی الگو یک فرایند شناختی است که در مغز ما زمانی که با برخی اطلاعاتی روبرو میشویم که با اطلاعات ذخیره شده در حافظه ما مطابقت دارد اتفاق می افتد. در علوم کامپیوتر، شناسایی الگو یک فرایند علمی است که…
یادگیری جمعی (ensemble learning)
یادگیری جمعی (ensemble learning) حوزهای در یادگیری ماشین است که در این حوزه تکنیکهایی مطرح شده است که به کمک آنها از چندین مدل به صورت ترکیبی و همزمان جهت تصمیم گیری استفاده میکنند تا توان مدل در تخمین خروجی…
چطور ویژگی استخراج کنیم؟
در این بخش میخواهیم مسئله اطلاعات مشترک رو بررسی کنیم. اطلاعات مشترک اطلاعاتی هستند که در پروژههای شناسایی الگو برای الگوریتمهای یادگیری ماشین گمراه کننده هستند و کار تصمیم گیری را برای این الگوریتمها دشوار میکنند. میخواهیم در این جلسه…
مروری مختصر بر الگوریتم نزدیکترین همسایه(KNN)
Knn مخفف عبارت k nearest neighbors است و برای تخمین خروجی داده جدید از k تا نزدیک ترین همسایه ی نمونه جدید در داده های آموزش کمک می گیرد.