
توضیح رویکرد ماشین بردار پشتیبان به زبان ساده
ماشین بردار پشتیبان(support vector machine) یکی از معروفترین الگوریتمهای یادگیری ماشین در مسائل طبقه بندی و البته رگرسیون هست. SVM به خاطر رویکرد منحصر به فردی که دارد باعث شده هم در مسائل طبقه بندی و هم در مسائل رگرسیون بهترین عملکرد را داشته باشد. میخواهیم در این مقاله با یک مثال بسیار ساده ایده SVM رو توضیح دهیم.
ماشین بردار پشتیبان در مسائل طبقه بندی
به عکس زیر توجه کنید… فرض کنید شما در بین دو دریا قرار گرفته اید و میخواهید در اون بخش خشکی بین دو دریا حرکت کنید… اگر بخواهید خیس نشوید به نظرتون بهترین جا برای راه رفتن و یا ایستادن کجا میتونه باشه؟

درسته دقیقا در وسط بین دو دریا قرار بگیرید بهترین جا خواهد بود! و بیشترین حاشیه امنیت رو خواهید داشت. حالا برای اینکه دقیقا در وسط بین دو دریا قرار بگیرید چیکار میکنید؟ فاصله بین دو دریا( ازآخرین جایی که آب دو دریا قطع شده) را محاسبه میکنید و دقیقا وسط بین دو دریارو پیدا میکنید و اونجا وای میاستید!
سوال اینه که چرا وسط رو انتخاب میکنید؟ چرا نزدیک یکی از دریاها قرار نمی گیرید؟ اونجا هم که خشکی هست و میشه اونجا هم وایساد و خیس نشد!
خب همه میدونیم که آب دریا مواج هست و درسته الان شاید یه جاهایی خشک باشه ولی بعضی مواقع جزر و مد باعث میشه که سطح آب بیاد بالا و تا یه حدی از خشکی زیر آب بره! در اون صورت ما کنار آب هر سمت وایسیم بعدا اونجا آب میاد و ما خیس می شیم! پس این تغییرات سطح آب مارو مجاب میکنه که در جایی بین دو دریا وایسیم که بیشترین فاصله رو به هر دو سمت داشته باشه! و این دقیقا وسط دریا هست. اگه اونجا وایسیم حاشیه امنیت زیادی خواهیم داشت و شانس خیس نشدن ما خیلی زیاده!
همین داستان در مباحث طبقه بندی هست! الگوریتمهای یادگیری ماشین براساس داده کار میکنند و تمام دانش آنها براساس پایگاه داده آموزشی هست! و واقعیت اینه که داده آموزشی بخش کوچکی از یک داده واقعی هست و ما در عمل داده ای خواهیم داشت که مقداری تغییرات نسبت به داده آموزشی خواهد داشت. مثل این میمونه که شما برای بررسی قد افراد جامعه ایران، تعدادی از افراد یک شهر رو انتخاب کرده اید و از آنها برای این مطالعه میخواهید استفاده کنید. مثلا 1000 نفر! این 1000 نفر بخش بسیار کوچکی از 80 میلیون ایرانی هستند! ولی خب چاره چیه! مدلهای یادگیری ماشین باید با همین داده محدودی که دارند بهترین عملکرد خود را باید ارائه بدهند.
حالا شما فرض کنید یک مسئله طبقه بندی دو کلاسه به صورت زیر دارید. و قراره که شما مرز تفکیک کننده بین دو گروه رو بدست بیاورید.
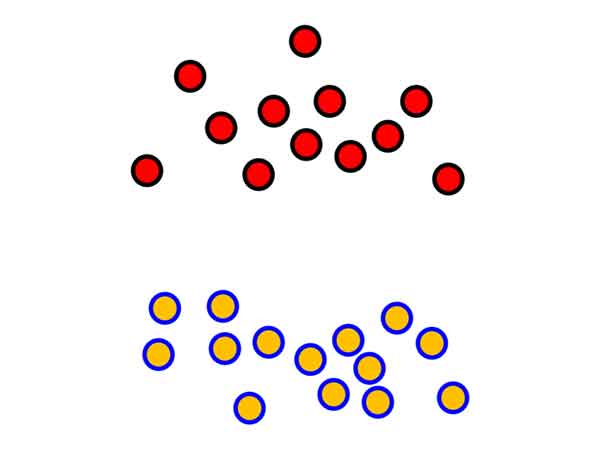
با علم به اینکه در عمل داده های جدید تغییراتی خواهند داشت، به نظر شما بهترین مرز چه مرزی میتونه باشه؟ اگه شما جای الگوریتم یادگیری ماشین باشید چه مرزی رو پیدا میکنید؟
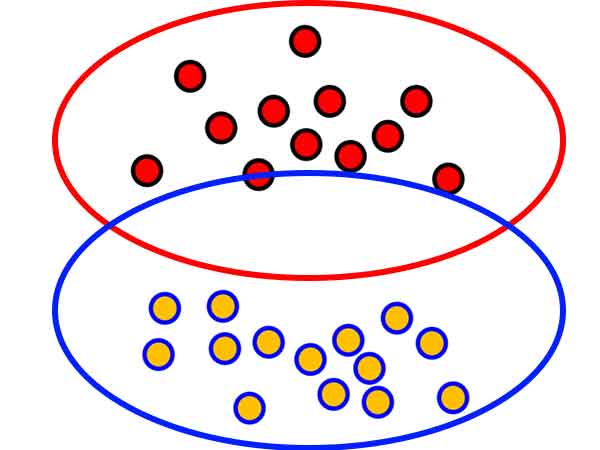
هدف از پیدا کردن مرز اینه که در عمل روی داده های واقعی هم خوب عمل کند! ملاک فقط داده آموزشی نیست! برای همین مرزی رو پیدا میکنید که به هر دو گروه بیشترین فاصله را داشته باشد!
برای اینکار از نزدیکترین نمونه های هر گروه(بردارهای پشتیبان) کمک میگیرید! و مرزی پیدا میکنید که بیشترین فاصله را با نزدیکترین نمونه های دو گروه داشته باشد. این ایده ای هست که آقای Vapnik در ماشین بردار پشتیبان به کار گرفتند. مرز بدست آمده بهترین مرز ممکن بین دو گروه هست. و در عمل هم عملکرد بهتری در مقابل داده تست خواهد داشت.
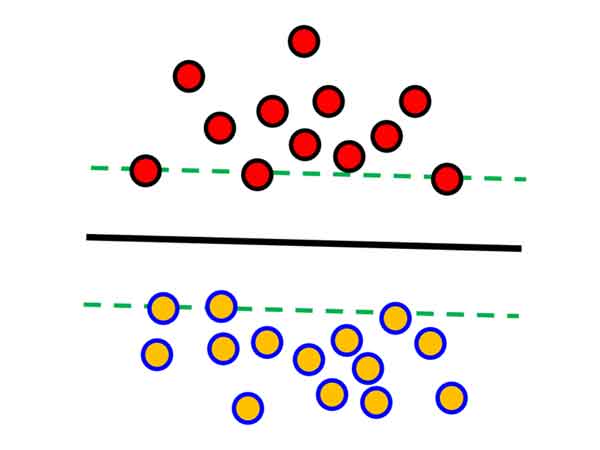
یکی از مزیتهای SVM اینه که مسئله بهینه سازی آن محدب هست، یعنی اگر مسئله جواب داشته باشد، SVM بهترین جواب ممکن را پیدا میکند. به عبارت دیگر اگر بین دو دریا خشکی وجود داشته باشد، SVM جایی وای میاسته که زمان بالا پایین رفتن آب دریا هم آب بهش نرسه و یا نهایتا خیلی کم برسه.
ماشین بردار پشتیبان در مسائل رگرسیون
در مسائل رگرسیون هم از ماشین بردار پشتیبان استفاده میکنند و همانند طبقه بندی عملکرد خیلی خوبی از خود ارائه داده هست. حال بیاید با یک مثال ساده ببینیم که ماشین بردار پشتیبان در مسائل رگرسیون با چه هدفی رابطه بین ورودی و خروجی را محاسبه میکند.
در بحث طبقه بندی مثال خشکی بین دو دریا رو زدیم، اینجا از مثال یک دریا(رودخانه) بین دو خشکی رو میزنیم. حال به شکل زیر نگاه کنید، فرض کنید سوار یک قایقی هستید که در یک رودخانه ای که دو طرفش خشکی هست حرکت میکنید. اینجا هدف شما چیه، هدف اینه که این قایق رو به مقصد برسونید و اگر به کنار رودخانه برسه آسیب میبینه. حالا به نظر شما قایق باید کجا حرکت کنه که خطری تهدیدش نکنه؟!

بله اینجا هم باید قایق اون وسط وسط حرکت کنه تا بیشترین حاشیه امنیت رو داشته باشه! حالا چجوری اون وسط قرار بگیریم؟ فاصله ی بین دو طرف خشکی رو محاسبه میکنیم. میگیم که قایق باید جایی حرکت کنه بیشترین فاصله رو با دو طرف خشکی داشته باشه!

حال به مثال زیر توجه کنید. در این مثال هدف این است که رابطه بین ورودی و خروجی را پیدا کنید. الان بهترین رابطه بین ورودی و خروجی چی خواهد بود؟ رابطه ای که دقیقا بین نمونه ها باشه. در بحث رگرسیون هدف مدلهای یادگیری ماشین اینه که رابطه ای پیدا کنند که دقیقا وسط نمونه ها باشه. و رفتار آنها را توصیف بکنه.
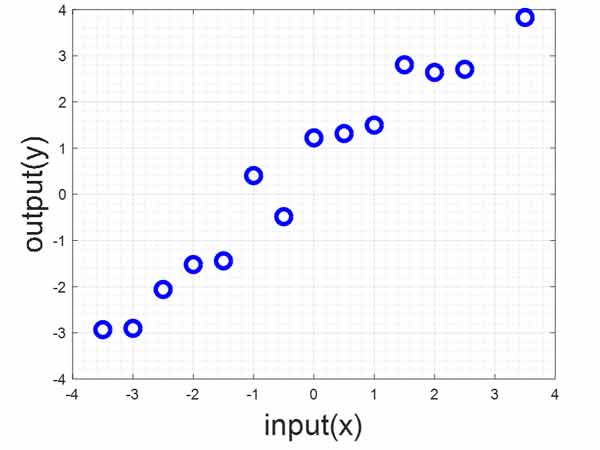
ماشین بردار پشتیبان در مسائل رگرسیون برای پیدا کردن چنین رابطه ای از دورترین نمونه های دو طرف(بردارهای پشتیبان) کمک میگیره(لبه ی خشکی ها). و رابطه بین ورودی و خروجی را طوری پیدا میکنه که بیشترین فاصله رو با این نمونه ها داشته باشد.
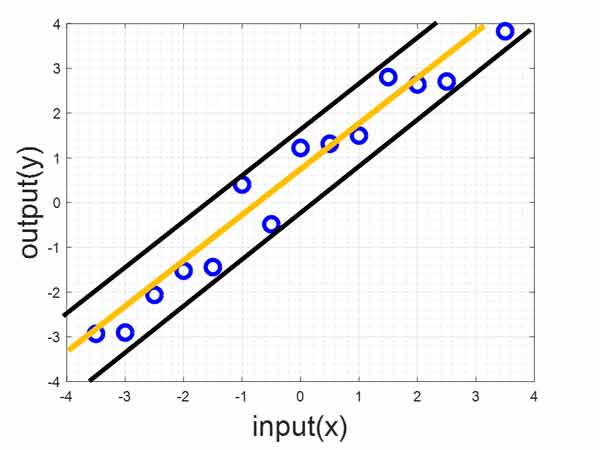
اگر بخواهیم رویکرد SVM رو در مسائل طبقه بندی و رگرسیون رو خیلی خلاصه توصیف کنیم، میگیم که SVM در مسائل طبقه بندی هدفش پیدا کردن مرزی هست در حاشیه امنیتش هیچ نمونه ای نباشد. به عبارت دیگر بین دو مرز کناری دریا هیچ آبی نباشد.
در بحث رگرسیون هم دنبال رابطهای هست که در آن همه نمونه ها در داخل حاشیه امینتش قرار بگیرند. به عبارتی دیگر بین دو مرز کنار خشکی، هیچ قسمت خشکی نباشد!
این توضیحات بخش کوچکی از مباحث فصل 4 دوره جامع شناسایی الگو-یادگیری ماشین هست. در این فصل به طور مفصل مباحث تئوری و ریاضیات ماشین بردار پشتیبان را هم در مسائل طبقه بندی و هم مسائل رگرسیون آموزش داده ایم، سپس به صورت مرحله به مرحله پیاده سازی کرده ایم و در پروژه های عملی استفاده کرده ایم. اگر علاقه مند به این موضوع هستید پیشنهاد میکنیم که این فصل را از دست ندهید.
دوره های مرتبط

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP

دیدگاه ها