
خواندن داده با فرمتهای مختلف در پایتون
در هر پروژهی یادگیری ماشین، در ابتدا لازم هست که داده را با کمک ابزاری خوانده و وارد محیط برنامه نویسی پایتون بکنیم. در پایتون کتابخانه های مختلفی هست که میتوانیم با کمکشون داده به فرمتهای مختلف را بخوانیم. در این پست توضیح میدهیم که چطور متیوان با استفاده از کتابخانه هایی نظیر NumPy، Pandas و SciPy داده به فرمتهای مختلف را وارد محیط برنامه نویسی پایتون کرد.
خواندن فایل تسکت (.txt) با کمک کتابخانه NumPy
برای خواندن یک فایل تکست از تابع زیر استفاده میکنیم. اسم فایل و مسیر را مشخص میکنیم و به تابع loadtxt میدهیم تا فایل را بخواند.
Python
import numpy as np filename =r'iris.txt' dataset= np.loadtxt(filename,delimiter='\t')
ورودی delimiter مشخص میکند که مقادیر هر سطر در فایل تکست به چه صورت از هم جدا شده اند. از آنجا که در فایل ما مقادیر در هر سطر با tap از هم جدا شده اند برای همین t\ در نظر گرفتیم.
نکته: تابع numpy.loadtxt فایل تسکت را خوانده و در یک آرایه نامپای قرار میدهد. اگر فایل تسکت حاوی متن و اعداد باشه خطا خواهد داد. چرا که ما در یک آرایه نامپای مقادیر از یک نوع را قرار میدهیم. پس همگی یا باید مقادیر عددی یا رشته ای باشند.
اگر فایل در جایی متفاوت با کد باشد، قبل اسم فایل مسیر رو هم مشخص میکنیم.
filename= r'C:\onlinebme\PyTorch\season03-Datasets and dataloaders\iris.txt'
خواندن فایل تسکت (.txt) با کمک کتابخانه Pandas
برای خواندن فایل تکست با کمک کتابخانه pandas به شکل زیر عمل میکنیم:
Python
import pandas as pd filename= 'iris.txt' df= pd.read_csv(filename,sep='\t',header=None)
ورودی sep مشخص میکند که مقادیر هر سطر فایل تکست به چه صورت از هم جدا شده اند.
برای اینکه متوجه بشیم که ورودی header را چی در نظر بگیریم، بهتره اول با ساختار داده در پانداس آشنا شویم. از دید پانداس قالب داده (data frame) به شکل زیر است.
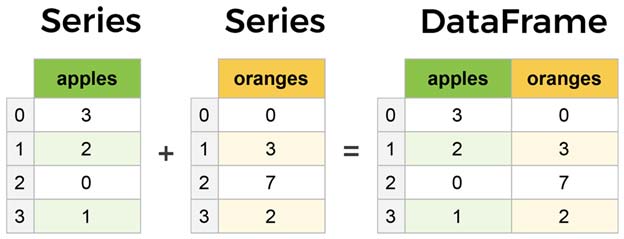
یک data frame از جدولی از مقادیر تشکیل شده است که این مقادیر هر مجموعه در هر ستون قرار گرفته است. برای مثال در بحث یادگیری ماشین میتونیم بگیم اطلاعات هر ویژگی در هر ستون قرار گرفته است. به عبارتی تعداد سطرها تعداد نمونه ها را مشخص میکند و تعداد ستونها تعداد ویژگی ها را. باز بستگی دارد که در فایل تسکت شما محتوا به چه صورت قرار گرفته باشد.
هر ستون یک اسمی دارد که با آن هم میتوان به محتوای هر ستون دسترسی پیدا کرد. برای دسترسی به سطرها هم کافیه آدرس اندیسی آنها را مشخص کنیم.
ورودی header مشخص میکند که سطر اول مشخص کننده چی هست، اگر header را مشخص نکنیم و یا ‘infer’ تعریف کنیم، در این صورت سطر اول مقادیرش هرچی باشد، به عنوان اسم هر ستون در نظر گرفته خواهد شد. از اونجا که در داده ما اسمی برای ستونها مشخص نشده، پس ما header را None در نظر میگیریم تا سطر اول رو به عنوان اسم ستونها در نظر گرفته نشود.
به شکل زیر میتوانیم از داخل data frame محتوا را جدا کنیم.
Python
data= df.iloc[:,:-1].to_numpy() label= df.iloc[:,-1].to_numpy()
خواندن فایل .data با کمک کتابخانه Pandas
خواندن فایل .data دقیقا مثل فایل txt است.
Python
import pandas as pd filename= 'iris.data df= pd.read_csv(filename,sep='\t',header=None)
خواندن فایل اکسل (.xlsx) با کمک کتابخانه Pandas
برای خواندن فایل اکس با پانداس از تابع زیر استفاده میکنیم.
Python
import pandas as pd filename= r'iris\iris.xlsx' df= pd.read_excel(filename,header=None)
اگر سطر اول فایل اکسل شما، مربوط به اسم ستونها است، در اینصورت header را یا تعریف نکنید و یا صفر قرار دهید.
خواندن فایل .mat با کمک کتابخانه SciPy
برای اینکه بتوانیم درک کنیم که چطور یک فایل .mat را میتوان وارد محیط پایتون کرد، لازم است اول بدانیم که داخل فایل .mat چه مقادیری و به چه صورت قرار گرفته اند.
در داخل فایل .mat یک دیکشنری هست که شامل یه سری key-value ها است. به عبارتی آرایههای نامپای یا متلب، با اسم مشخص در داخل یک دیکشنری قرار گرفته اند.
ما بعد از لود کردن فایل، به یک دیکشنری دسترسی خواهیم داشت که کافیه اسم کلید را بدهیم، و به مقادیر آرایه مد نظر دسترسی داشته باشیم.
با کمک ماژول io (input-output) کتابخانه SciPy میتوانیم فایل .mat را بخوانیم.
Python
from scipy import io filename= r'iris\iris.mat' dic= io.loadmat(filename) features= dic['data'] target= dic['label']
از اونجا که در داخل فایل .mat دو تا آرایه به اسم data و label ذخیره شده بود، برای همین از داخل دیکشنری اون آرایه ها را ورمیداریم. برای اینکه بدونیم داخل یک دیکشنری چه فایلهایی هست، میتونیم به این شکل عمل کنیم.
Python
ds.keys() dict_keys(['__header__', '__version__', '__globals__', 'data', 'label'])
اونایی که بدون ___ هستند، اسم کلید آرایه هایی هست که داخل فایل قرار گرفته است.
بعد از اینکه داده ها را خواندیم آنها را میتوانیم در تنسورهای پایتورچ قرار دهیم و سپس شبکه های عصبی را روی آنها اعمال کنیم. در پست “تفاوت تنسورهای PyTorch با آرایه های NumPy” نحوه تبدیل آرایه های NumPy به تنسورهای PyTorch را توضیح داده ایم.
دوره های مرتبط

دوره پردازش سیگنال قلبی ECG

پردازش سیگنال مغزی با کتابخانه MNE پایتون

پیادهسازی شبکه های عصبی با پایتورچ PyTorch

برنامه نویسی شیء گرا در پایتون Python

کتابخانه NumPy و matplotlib در پایتون

با سلام
در خط اول که می فرمائید ” اسم فایل و مسیر را مشخص میکنیم” چگونه اینکار را انجام می دهید. لطفا توضیح دهید . ممنونم
سلام
همون اوایل یک نمونه مثال آوردیم که چطور میشه مسیر و اسم فایل رو مشخص کرد:
filename= r’C:\onlinebme\PyTorch\season03-Datasets and dataloaders\iris.txt’
در این مثال، اول مسیری که فایل تکست قرار داره رو کامل مشخص کردیم، بعدش در انتها هم اسم فایل به هم فرمتش رو مشخص کردیم. بقیه هم دقیقا به همین طور هست.