
فیسبوک ادعا میکند که ربات جدید آنها ربات گفتگوی گوگل را شکست داده است!
لازم بذکر است که برای انجام تحقیقات بیشتر ، سیستم هوش مصنوعی را به حالت منبع باز قرار داده است.
با وجود تمام پیشرفت هایی که ربات های گفتگو و دستیاران مجازی انجام داده اند، هنوز هم به عنوان مکالمه کننده های بسیار بدی شناخته می شوند. بیشتر آن ها بسیار وظیفه گرا(تسک محور) هستند. این به این معناست که شما در رابطه با آن چه که مورد نیاز شماست تقاضا می کنید و آن ها هم تقاضای شما را برآورده می کنند. برخی از آنها بسیار ناامید کننده هستند به طوری که به نظر می رسد که آن ها هرگز قرار نیست تا آنچه که به دنبالش هستید را برای شما فراهم کنند. برخی دیگر به شدت خسته کننده و حوصله سر بر هستند. این در حالی است که آن ها فاقد هرگونه جذابیت همنشینی و معاشرت برای انسان می باشند.
نویسنده: امیررضا جهانی
وقتی برای تنظیم زنگ هشدار ساعت خود از این ربات ها استفاده می کنید، میزان رضایت شما را به طور قابل توجهی افزایش می دهند. اما هرچقدر که آن ها به عنوان واسطه هایی جهت انجام امور مختلف، مانند خرده فروشی تا مراقبت های بهداشتی و خدمات مالی به کار گرفته می شود، به طور فزاینده ای معروف می شوند ، تنها کمبودها و عدم کفایتشان در قبال این نوع وظایف آشکارتر می شود.
اکنون شرکت فیسبوک یک ربات گفتگوی جدید و منبع-باز (Open-Source)ایجاد کرده است که ادعا می کند تقریباً در مورد هر چیزی با روشی جذاب و جالب صحبت می کند. Blender نه تنها به دستیاران مجازی کمک می کند تا بسیاری از کاستی های خود را برطرف کنند، بلکه پیشرفت را به سمت جاه طلبی بیشتر در بخش اعظم تحقیقات هوش مصنوعی که تکثیر هوش میباشد، سوق می دهد.
استفان رولر ، مهندس تحقیق در فیسبوک که همکاری این پروژه را بر عهده داشت، می گوید: “گفتگو به نوعی یک مسئله ” هوش مصنوعی کامل” است. او ادامه داد:” شما برای اینکه بخش گفتگو هوش مصنوعی را حل کنید، باید به حل کردن تمام بخش های هوش مصنوعی بپردازید و اگر گفتگو را حل کنید ، در واقع تمام هوش مصنوعی را حل کرده اید.”
توانایی Blender از مقیاس گسترده داده های آموزش آن ناشی می شود. این نخستین بار در 1.5 میلیارد مکالمه Reddit، آموزش داده شد تا پایه و اساس ایجاد پاسخ در گفتگو فراهم شود.
سپس با مجموعه داده های اضافی برای هر سه مهارت تنظیم شد: مکالمه هایی که حاوی نوعی احساسات بودند ، برای آموختن آن به ابزار همدلی (برای مثال اگر یک کاربر بگوید “من پیشرفت کردم”، می تواند در پاسخ به ای جمله بگوید، ” تبریک می گویم! “)؛ همچنین مکالمات انبوه با یک فرد متخصص، برای آموزش دانش و مکالمه بین افراد با شخصیت های متفاوت و مشخص، برای آموزش مورد تنظیم قرار گرفت.
مدل به دست آمده 3.6 برابر بزرگتر از ربات گفتگو Meena شرکت گوگل می باشد که در ماه ژانویه اعلام شد. این مدل آنقدر بزرگ است که نمی تواند در یک دستگاه واحد قرار بگیرد و در عوض باید بین دو تراشه محاسباتی اجرا شود.
در آن زمان ، گوگل اعلام كرد كه Meena بهترین ربات گفتگو جهان است. با این حال، در آزمایشات مربوط به شرکت فیسبوک، 75٪ از افرادی که Blender را مورد ارزیابی قرار دادند، آن را جذاب تر از Meena می دانند و 67٪ از آنها نظر بر این دارند که Blenderشبیه به یک انسان است تا یک ربات. این ربات گفتگو همچنین 49٪ از اشخاصی که وقتشان جهت ارزیابی صرف میشد را فریب می داد و همچنین به این نتیجه رسیدند که گزارش های مکالمه ربات، بسیار بیشتر از مکالمه بین افراد واقعی، شبیه به انسان بود. به این معنی است که تفاوت کیفی زیادی بین این دو ربات وجود ندارد و همچنین شرکت گوگل تا زمانی که قرار بود این خبر منتشر شود به هیچ درخواستی جهت اظهار نظر پاسخ نداده است.
با وجود این نتایج چشمگیر مهارت های Blender هنوز هم در نزدیکی مهارت های یک انسان قرار ندارند. تاکنون این تیم، ربات گفتگو Blender را فقط در مکالماتی کوتاه با 14 نوبت ارزیابی کرده است. محققان گمان می کردند، در صورتی که ربات مدت طولانی تری را برای گفتگو صرف کند در زمان کوتاهی بخش معنایی مکالمه ربات توقف می یابد. امیلی دینان ، رهبر دیگر پروژه می گوید: “این مدل ها قادر به دسترسی عمیق و جامع نبوده و همچنین قادر به یادآوری تاریخ مکالمه انجام شده در چند نوبت نمی باشند.”
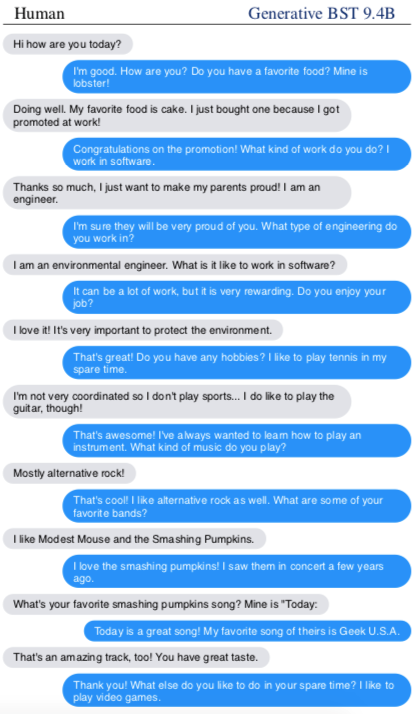
نمونه ای از مکالمه بین انسان و ربات Blender
Blender همچنین تمایل به ایجاد دانش از طریق توهم و حالت هذیانی و یا ایجاد حقایق دارد. این عملکرد یک محدودیت مستقیم از تکنیک های یادگیری عمیق است که در این ربات برای ساخت این نوع موارد استفاده می شود و در نهایت جملات خودش را به جای پایگاه داده دانش، از همبستگی آماری تولید می کند. در نتیجه، می تواند به عنوان مثال توضیحی مفصل و منسجم از یک فرد مشهور را با اطلاعاتی که حداکثر صحیح می باشد بیان کند. این تیم قصد دارد با ادغام یک پایگاه داده دانش در این ربات گفتگو، تولید پاسخ را مورد آزمایش قرار دهد.

ارزیاب های انسانی مکالمات چند نوبت را با ربات های گفتگوی مختلف مقایسه کردند.
یکی دیگر از چالش های مهم در هر سیستم ربات گفتگو ، جلوگیری از گفتن موارد مغرضانه است. از آنجایی که در نهایت چنین سیستم هایی در رسانه های اجتماعی آموزش داده می شوند، می توانند مجدداً از انتقادات بی رحمانه و تلخی که در فضای اینترنت وجود دارند استفاده کنند. (این اتفاق ناعادلانه در مورد ربات گفتگو مایکروسافت نیز در سال 2016 رخ داده است.) این تیم در حل این مسئله با جمعیتی از پرسنل خود سعی داشت تا از سه مجموعه داده ای که برای تنظیم دقیق از آن استفاده می کرد، زبان مضر را فیلتر کنند. اما همین کار را برای مجموعه داده Reddit به دلیل اندازه ای که داشت نتوانست انجام دهد. (هرکسی که زمان زیادی را صرف Reddit کرده است می داند که چرا این مسئله می تواند مشکل ساز باشد.)
این تیم امیدوار است که ربات را با مکانیزم های ایمنی بهتری از جمله طبقه بندی کننده های زبان مضر آزمایش کند که این موضوع می تواند پاسخ ربات گفتگو را دو بار مورد بررسی قرار دهد. محققان اذعان می کنند که این رویکرد جامع نخواهد بود. بعضی اوقات جملاتی مانند “بله ، عالی است” می تواند خوب به نظر برسد ، اما در یک زمینه حساس مانند پاسخ به یک اظهار نژاد پرستی، می تواند معنای مضری را به بار آورد.
در دراز مدت ، تیم هوش مصنوعی فیسبوک همچنین علاقه مند به ساختن مکالمه های پیچیده تر و مکالمه ای است که می تواند فقط به نشانه های بصری و همچنین کلمات پاسخ دهد. به عنوان مثال ، یک پروژه در حال توسعه سیستمی به نام Image Chat (چت تصویری) است که می تواند به طور معقول و منطقی، در رابطه با عکس هایی که ممکن است کاربر ارسال کند، ارتباط برقرار کند.
دوره های مرتبط





دوره پردازش سیگنال قلبی ECG

پردازش سیگنال مغزی با کتابخانه MNE پایتون

پیادهسازی شبکه های عصبی با پایتورچ PyTorch

دیدگاه ها