EEGNet: یک شبکه عصبی کانولوشنی فشرده برای BCIهای مبتنی بر EEG
- دسته:اخبار علمی
- هما کاشفی
در این مقاله، EEGNet را معرفی میکنیم که یک شبکه CNN فشرده برای کلاسبندی و تفسیر BCIهای مبتنی بر EEG است. کاربرد کانولوشنهای Depthwise و Separable که قبلاً در حوزهی بینایی ماشین استفاده میشده را برای ساخت یک شبکه خاص EEG معرفی میکنیم که چندین مفهوم شناخته شدهی استخراج ویژگی EEG را در بر میگیرند مانند فیلترهای مکانی بهینه و ساخت بانک فیلتری و در عین حال به طور همزمان تعداد پارامترهای قابل آموزش در این شبکه در مقایسه با رویکردهای موجود کاهش مییابد.
در مقالهی اصلی EEGNet (DOI 10.1088/1741-2552/aace8c) قابلیت تعمیم شبکه EEGNet روی دیتاستهای EEG جمع آوری شده از چهار پارادایم BCI مختلف ارزیابی شدهاند. این دیتاست ها شامل موارد زیر هستند: پتانسیل انگیختهی بصری P300، error-related negativity (ERN)، پتانسیل قشر مربوط به حرکت (MRCP) و ریتم حسی حرکتی (SMR) که طیفی از پارادایمها را بر اساس کلاسبندی پتانسیلهای مربوط به رویداد (P300, ERN, MRCP) و همچنین کلاسبندی اجزای نوسانی (SMR) نشان میدهد. علاوه بر این هر یک از این مجموعههای داده حاوی مقادیر متفاوتی از داده ها هستند. امکانی فراهم میآورند تا بتوان کارایی EEGNet را روی انواع مختلف داده بررسی کرد.
نویسندگان مقاله EEGNet نشان دادهاند که این شبکه چطور عملکرد کلاسبندی را در تقریباً تمام پارادایمهای تست شده بهبود میدهد. به خصوص زمانی که دادههای آموزشی کمی در دسترس است.
علاوه بر این نشان داده اند که EEGNet به طور موثر در تمام پارادایمهای آزمایش شده تعمیم مییابد. همچنین EEGNet به خوبی یک مدل CNN برای پارادایمهای خاص EEG عمل میکند اما با پارامترهای کمتر که نشاندهندهی استفادهی کارآمدتر از پارامترهای مدل است. در نهایت با استفاده از تجسم سازی ویژگی و تحلیل فرسایشی مدل، نشان دادهاند که میتوان از مدل EEGNet، ویژگیهای تفسیرپذیر نوروفیزیولوژیکی استخراج کرد. این مهم است زیرا CNNها علیرغم توانایی خود برای استخراج ویژگیهای قوی و خودکار، اغلب ویژگیها را به سختی تفسیر میکنند. برای متخصصان علوم اعصاب، توانایی کسب بینش در مورد پدیدههای عصبی فیزیولوژیکی مشتق شده از CNN بسیار مهم است. و ممکن است به اندازه دستیابی به عملکرد طبقه بندی خوب، مهم باشد. نویسندگان مقاله EEGNet توانایی معماری خود را برای استخراج سیگنالهای قابل تفسیر نوروفیزیولوژیکی در چندین پاراداریم BCI تأیید کردهاند.
EEGNet: معماری CNN فشرده
شبکه EEGNet یک معماری فشرده CNN برای BCIهای مبتنی بر EEG است. میتوان آن را در پارادایمهای مختلف به کار برد و با دادههای بسیار محدود آموزش داد و این شبکه میتواند ویژگیهای تفسیرپذیر نوروفیزیولوژیکی ایجاد کند. در این مدل از بهینه ساز Adam و پارامترهای پیش فرض استفاده شده است و تابع خطای categorical cross entropy را کاهش داده است. مدل با 500 تکرار آموزشی اجرا شده و از رویکرد Stopping استفاده شده که وزنهای مدل را در بهترین حالت ذخیره میکند. همچنین واحدهای بایاس در تمام لایههای کانولوشنی حذف شدهاند. لازم به ذکر است در حالیکه همه ی کانولوشنها یک بعدی هستند، برای سهولت پیاده سازی نرم افزاری از توابع کانولوشن دو بعدی استفاده شده است. پیاده سازی نرم افزار در https://github.com/vlawhern/arl-eegmodels آمده است.
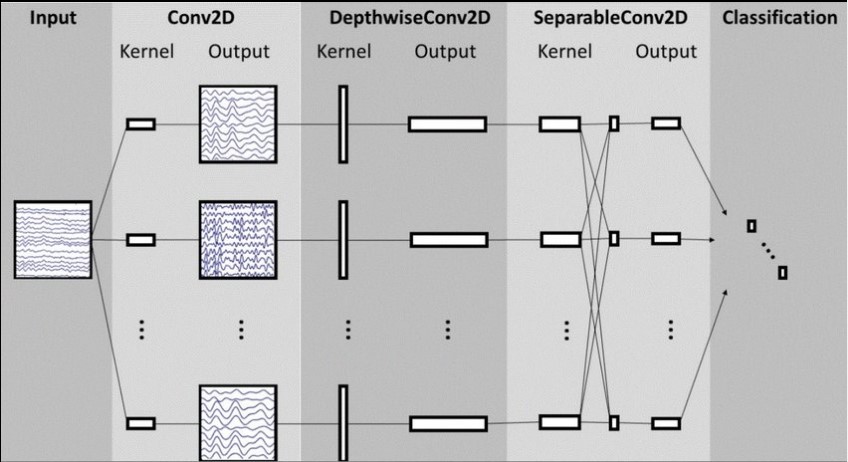
ساختار کلی معماری شبکه EEGNet. خطوط نشاندهنده ی اتصال کرنل کانولوشنی بین ورودیها و خروجیها هستند (یعنی feature map). این شبکه با یک کانولوشن زمانی آغاز میشود (ستون دوم) تا فیلترهای فرکانس را یاد بگیرد. سپس یک کانولوشن depthwise استفاده میشود (ستون وسط) که به هر feature map به طور جداگانه متصل است تا فیلترهای مکانی خاص فرکانس را یاد بگیرد. کانولوشن separable (ستون چهارم) ترکیبی از یک کانولوشن depthwise است که خلاصه زمانی هر feature map را به طور جداگانه یاد میگیرد. و پس از آن یک کانولوشن pointwise قرار دارد که یاد میگیرد چطور feature mapها را با یکدیگر ترکیب کند.
توضیح دقیق معماری شبکه EEGNet در مقاله
در مقاله آمده است:
*در بلوک 1، دو گام کانولوشنی را به صورت توالی انجام میدهیم. ابتدا F1تا فیلتر کانولوشنی دو بعدی به سایز (1,64) اعمال میکنیم که طول فیلتر نصف فرکانس نمونه برداری داده در نظر گرفته شده است (در این جا 128Hz) و خروجی آن F1 تا ویژگی است که حاوی سیگنال EEG در فرکانس میانگذر است. اینکه طول کرنل زمانی را نصف نرخ نمونه برداری قرار دادیم به ما این امکان را داد تا اطلاعات فرکانسی در 2 هرتز و بالاتر را بدست آوریم. سپس از یک Depthwise Convolution به سایز (C,1) استفاده کردیم تا فیلتر مکانی را یاد بگیریم. در کاربردهای CNN برای بینایی ماشین، مهمترین مزیت استفاده از یک کانولوشن Depthwise، کاهش تعداد پارامترهای قابل آموزش است زیرا این کانولوشنها به feature mapهای قبلی تماماً متصل نیستند. مهمتر از آن، این عملیات زمانی که در کاربردهای خاص EEG استفاده میشود راهی مستقیم برای یادگیری فیلترهای مکانی هر فیلتر زمانی فراهم میآورد و امکان استخراج موثر فیلترهای مکانی خاص فرکانس را فراهم میآورد. پارامتر عمق D تعداد فیلترهای مکانی برای یادگیری هر feature map را نشان میدهد. این توالی کانولوشنی دو مرحلهای از الگوریتم Filter Bank Common Spatial Pattern (FBCSP) الهام گرفته شده است و ماهیت آن مشابه روش دیگر تحلیل مولفههای منفک است. ما هر دو کانولوشن را به صورت خطی حفظ کردیم زیرا دیدیم زمانی که از فعالسازیهای غیرخطی استفاده میکردیم هیچ بهبودی در عملکرد حاصل نشده است. ما Batch Normalization را در امتداد بعد feature map اعمال کردیم قبل از اینکه فعالسازی واحد خطی نمایی (ELU) را اعمال کنیم. و برای بهبود عملکرد مدل از Dropout استفاده کردیم. نرخ Dropout را برای کلاسبندی within-subject برابر با 0.5 قرار دادیم تا از بیش برازش مدل هنگام آموزش روی نمونههای کوچک جلوگیری کنیم و احتمال بیش برازش را برای کلاسبندی cross-subject برابر با 0.25 قرار دادیم. ما یک لایهی average pooling به سایز (1,4) را اعمال کردیم تا نرخ نمونه برداری سیگنال را به 32 هرتز کاهش دهیم.
* در بلوک 2، از Separable Convolution که یک Depthwise Convolution است استفاده کردیم (در اینجا به سایز (1.16) که 500 میلی ثانیه فعالیت EEG را در 32 هرتز نشان میدهد) و پس از آن F2 تا کانولوشن Pointwise (1,1) قرار دارد. مزیت اصلی کانولوشنهای separable به ترتیب عبارتند از: 1)کاهش تعداد پارامترها برای آموزش و 2)جداسازی رابطه بین و در امتداد feature mapها با یادگیری کرنلی که هر feature map را خلاصه میکند و سپس خروجیها را ادغام میکند. این عملیات هنگامی که برای کاربردهای خاص EEG استفاده میشود یاد میگیرد که چطور تک تک feature mapها را در واحد زمان خلاصه سازی کند (depthwise convolution). و اینکه چطور به صورت بهینه feature mapها را ادغام کند (Pointwise Convolution). این عملیات به صورت خاص برای سیگنالهای EEG مفید است. زیرا feature mapهای مختلف، داده را در مقیاسهای زمانی مختلفی نشان میدهند. در این مورد ابتدا یک خلاصهی 500 میلی ثانیهای از هر feature map را یاد میگیریم. و پس از آن خروجیها را با هم ترکیب میکنیم. یک لایهی Average Pooling به سایز (1,8) برای کاهش ابعاد استفاده میشود.
*در بلوک کلاسبندی، ویژگیها مستقیماً به کلاسبند Softmax با N واحد داده میشوند. N تعداد کلاسها در داده است. ما لایهی dense را برای تجمع ویژگی قبل از لایهی کلاسبندی softmax حذف کردهایم تا تعداد پارامترهای آزاد در این مدل را کاهش دهیم.
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

اصول برنامه نویسی پایتون Python

دیدگاه ها