
حاشیه نویسی داده: تعریف، ابزارها و دیتاستها
- دسته:اخبار علمی
- هما کاشفی
داده، بخش جدایی ناپذیر همهی الگوریتمهای یادگیری ماشین و یادگیری عمیق است. داده همان چیزی است که الگوریتمهای پیچیده را به سمت عملکردهای پیشرفته و بهبودیافته سوق میدهد. با این حال، اگر قصد دارید مدلهای هوش مصنوعی واقعاً قابل اعتماد بسازید، باید الگوریتمهایی را با دادههای ساختاربندی شده و برچسب گذاری شدهی مناسب ارائه دهید. اینجاست که فرآیند حاشیهنویسی یا annotation وارد عمل میشود. باید دادهها را حاشیهنویسی کنید تا سیستمهای یادگیری ماشین بتوانند از آنها برای نحوهی انجام تسکها استفاده کنند. حاشیه نویسی دادهها ساده است اما ممکن است آسان نباشد. ما میخواهیم شما را در این فرآیند راهنمایی کنیم و بهترین روشهای خود را به اشتراک بگذاریم که باعث صرفهجویی در وقت شما شود.
حاشیه نویسی داده چیست؟
اساساً حاشیه نویسی به معنی برچسب زدن ناحیه یا ناحیهی موردنظر است. این نوع حاشیه نویسی به طور خاص در تصاویر و ویدیوها یافت میشود. از سوی دیگر، حاشیه نویسی دادههای متنی تا حد زیادی شامل افزودن اطلاعات مرتبط، مانند متادیتا (ابرداده) و تخصیص آنها به یک کلاس خاص است. در حوزهی یادگیری ماشین، تسک حاشیه نویسی دادهها در دستهی یادگیری نظارت شده قرار میگیرد جایی که الگوریتم یادگیری، ورودی را به خروجی ارتباط میدهد و خود را برای کاهش خطاها بهینه میکند.
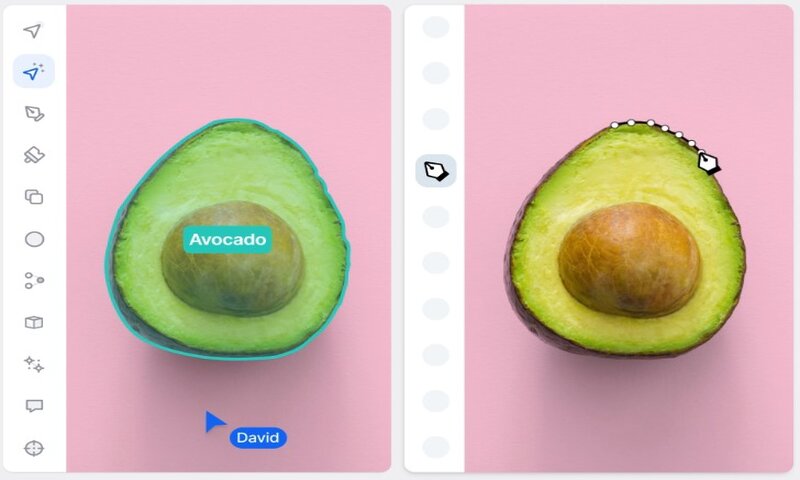
انواع حاشیه نویسی دادهها
در ادامه انواع مختلف حاشیه نویسی دادهها ارائه میشود.
حاشیه نویسی تصویر (Image Annotation)
حاشیهنویسی تصویر همان تسک حاشیهنویسی تصویر با برچسب است. این تسک تضمین میکند که یک الگوریتم یادگیری ماشین، ناحیهی حاشیه بندی شده را به عنوان یک شی یا کلاس مجزا در تصویر مشخص میکند. این تسک شامل ایجاد bounding box (برای تشخیص شی یا object detection) و ماسکهای سگمنتبندی (برای semantic segmentation و instance segmentation) است تا کلاسهای مختلف را از هم متمایز کند. در ابزار V7، شما میتوانید تصاویر را با استفاده از ابزارهایی چون نقطه، مکعبهای سه بعدی، خط و قلم مو، حاشیهنویسی کنید.
حاشیهنویسی تصویر اغلب برای ایجاد مجموعه دادههای آموزشی برای الگوریتمهای یادگیری ماشین استفاده میشود. این مجموعه دادهها برای ساخت سیستمهای مجهز به هوش مصنوعی مانند ماشینهای خودران، ابزارهای تشخیص سرطان پوست یا هواپیماهای بدون سرنشین که آسیب را ارزیابی میکنند یا تجهیزات صنعتی را بازرسی میکنند استفاده میشوند.
حال بیایید انواع مختلف روشهای حاشیه نویسی تصویر را بررسی و درک کنیم.
Bounding Box
روش Bounding Box به معنی رسم یک مستطیل اطراف جسمی خاص در تصویر موردنظر است. لبههای مستطیل باید بیرونیترین پیکسلهای جسم برچسب گذاری شده را لمس کند. در غیر اینصورت، شکافها مغایرتهای IoU یا همان Intersection Over Union ایجاد میکند و ممکن است مدل شما در سطح بهینهی خود عمل نکند.

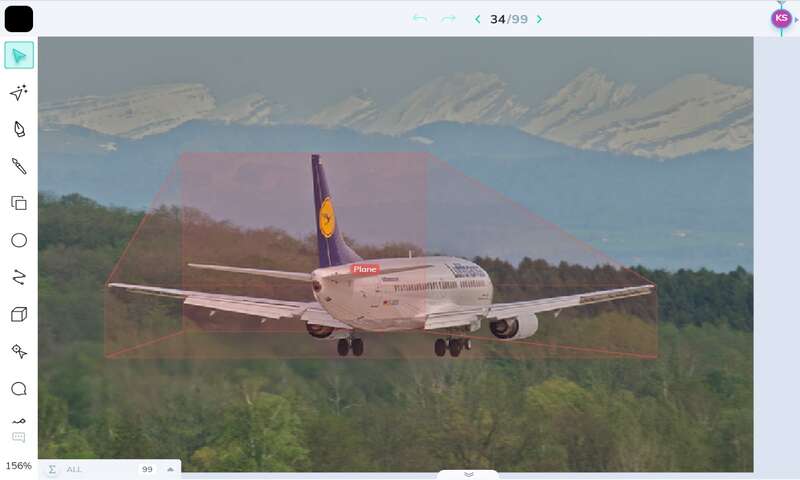
مکعبهای سه بعدی (3D Cubic)
حاشیهنویسی مکعب سه بعدی مشابه با حاشیهنویسی Bounding Box است. اما علاوه بر ترسیم مستطیل دوبعدی اطراف جسم موردنظر، کاربر باید فاکتور عمق را نیز در نظر بگیرد. از این روش میتوان در حاشیه نویسی اشیایی مانند هواپیماهای مسطح که نیاز به پیمایش دارند استفاده کرد همچنین اتومبیلها و یا اشیای دیگر.
برای آموزش انواع مدلهای زیر میتوانید با مکعبها حاشیه نویسی کنید:
-تشخیص شی (Object Detection)
-تخمین مکعبی سه بعدی (3D Cuboid Estimation)
-تخمین موقعیت 6DoF (6DoF Pose Estimation)
در تصویر زیر یک هواپیما با روش مکعبی حاشیه نویسی شده است.
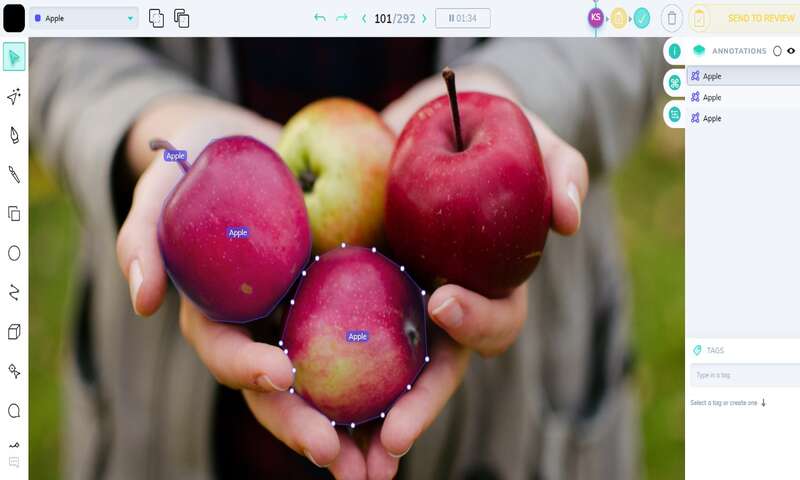
چندضلعیها (Polygon)
در حین ایجاد یک مکعب سه بعدی یا یک Bounding box ممکن است متوجه شده باشید که اشیا به طور ناخواسته در ناحیهی حاشیه نویسی گنجانده شوند. این وضعیت چندان ایدهآل نیست. چون باعث سردرگمی مدل یادگیری ماشین شود و در نتیجه اشیا را به اشتباه طبقهبندی کند. خوشبختانه برای جلوگیری از این وضعیت، راهی وجود دارد: اینجاست که چندضلعیها به کار میآیند و چیزی که باعث میشود این ابزار بسیار موثر شود توانایی آن در ایجاد یک ماسک در اطراف شی موردنظر در سطح پیکسل است. به راحتی میتوانید ابزار Polygon یا چندضلعی را انتخاب کنید. شروع به کشیدن یک خط از نقاط در اطراف جسم موردنظر در تصویر کنید. نیازی نیست که خط کامل باشد، زیرا هنگامی که نقاط شروع و پایان در اطراف جسم به هم متصل میشوند، چندضلعی ساخته خواهد شد.
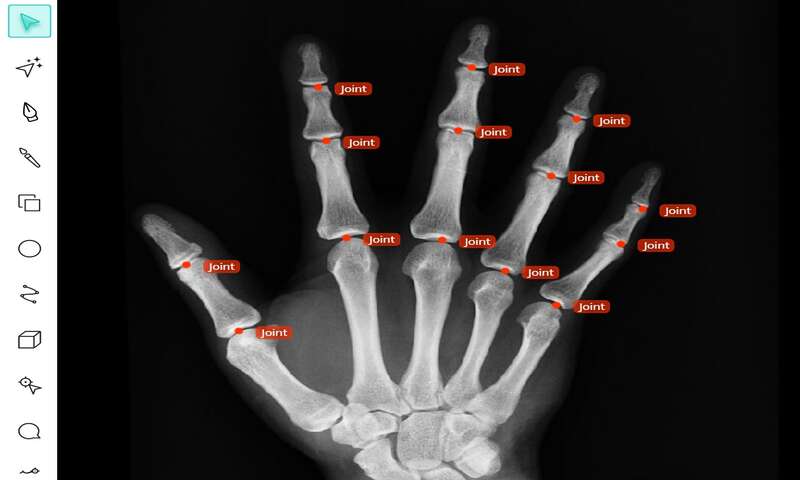
ابزار نقاط کلیدی (Keypoint tool)
حاشیهنویسی نقطه کلیدی، روش دیگری برای حاشیه نویسی یک شی با یک سری و یا مجموعهای از نقاط است. این نوع روش در تشخیص وضعیت قرارگیری دست (Hand gesture detection)، تشخیص نقطه عطف چهره (Facial landmark detection) و ردیابی حرکت (motion tracking) بسیار مفید است. نقاط کلیدی را میتوان به تنهایی یا به صورت ترکیبی استفاده کرد. یک نقشه نقطهای تعریف کرد که موقعیت شی موردنظر را مشخص میکند.
ابزار چندخطی (Polyline)
ابزار چندخطی به کاربر این امکان را میدهد تا دنبالهای از خطوط به هم پیوسته ایجاد کند. روند کار این ابزار به این شکل است که هر نقطه با پیوستن نقطهی فعلی به نقطهی قبلی یک خط ایجاد میکند. میتوان از آن برای حاشیه نویسی جادهها، خط کشی، علائم راهنمایی و رانندگی و غیره استفاده کرد.

سگمنتبندی معنایی (Semantic Segmentation)
سگمنتبندی معنایی یعنی گروهبندی بخشها یا پیکسلهای مشابه شی در یک تصویر مشخص. حاشیه نویسی دادهها با استفاده از این روش به الگوریتمهای یادگیری ماشین امکانی را میدهد تا ویژگی مشخص را یاد بگیرند و درک کنند. همچنین به کلاسبندی ناهنجاریها در تصویر کمک میکند.
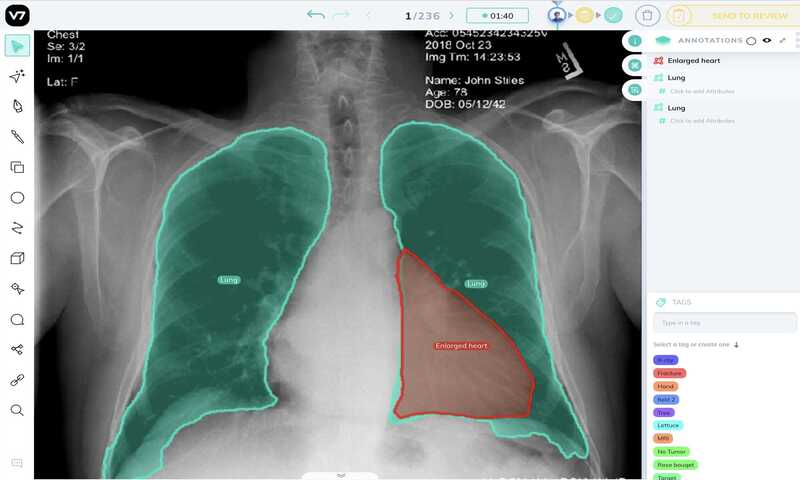
سگمنتبندی معنایی در زمینهی پزشکی بسیار مفید است جایی که رادیولوژیستها از آن برای حاشیه نویسی اسکنهای X-Ray, MRI, CT استفاده میکنند تا ناحیهی موردنظر را شناسایی کند. اینجا نمونهای از حاشیه نویسی با اشعه ایکس قفسه سینه آورده شده است.
حاشیه نویسی ویدیو
مشابه حاشیه نویسی تصویر، حاشیه نویسی ویدیو نیز تسک برچسب گذاری بخشها یا کلیپها در ویدیو است تا اشیا موردنظر فریم به فریم شناسایی و کلاسبندی شوند. حاشیهنویسی ویدیو از تکنیکهای مشابه حاشیه نویسی تصویر استفاده میکند مانند Bounding box یا Semantic Segmentation اما اینجا همه چیز فریم به فریم انجام میشود. این یک تکنیک ضروری برای تسکهای بینایی ماشین مانند محل یابی و ردیابی اشیا است.
حاشیه نویسی متن (Text Annotation)
حاشیه نویسی داده در تسکهای مربوط به پردازش زبان طبیعی (NLP) نیز ضروری است.
حاشیه نویسی متن به افزودن اطلاعات مرتبط در مورد دادههای زبانی اشاره دارد و برای این منظور برچسبها یا متادیتا را به دادهها اضافه میکند. برای درک بهتر حاشیه نویسی متن دو مثال را در نظر میگیریم.
1-تخصیص برچسبها
افزودن برچسب به معنی اختصاص یک جمله با کلمهای است که نوع آنها را توصیف میکند. میتوان جمله را به صورت احساسی، فنی و… توصیف کرد. برای مثال، میتوان برچسب مانند «خوشحالی» را به این جمله اختصاص داد «من از این محصول راضی هستم، عالی است».
2-افزودن متادیتا
به طور مشابه، در جملهی «میخواهم امشب یک پیتزا سفارش بدهم» میتوان اطلاعات مرتبطی برای الگوریتم یادگیری اضافه کرد تا بتواند کلمات خاصی را اولویت بندی کند و روی آن تمرکز کند. به عنوان مثال اطلاعاتی چون
«میخواهم امشب (زمان) پیتزا (غذا) سفارش دهم»
حال بیایید به طور خلاصه انواع مختلف حاشیهنویسی متن را بررسی کنیم.
حاشیه نویسی احساسات (Sentiment Annotation)
حاشیه نویسی احساسات چیزی نیست جز تخصیص برچسبهایی که نشاندهندهی احساسات انسانی چون غم، شادی، عصبانیت، احساسات مثبت و منفی و خنثی و … است. حاشیه نویسی احساسات در هر تسک مرتبط با تحلیل احساسات کاربرد پیدا میکند (مانند خرده فروشی برای سنجش رضایت مشتری بر اساس حالات چهره او)
حاشیه نویسی قصد و نیت (Intent Annotation)
حاشیهنویسی قصد نیز برچسبهایی را به جملات اختصاص میدهد اما بر قصد یا میل پشت جمله تمرکز میکند. برای مثال، در سناریوی خدمات مشتری، پیامی مانند «من باید با سام صحبت کنم» میتواند تماس را به تنهایی به سام هدایت کند یا پیامی مانند «من نگران کارت اعتباری هستم» میتواند تماس را به تیم هدایت کند تا به مسائل مربوط به کارت اعتباری رسیدگی کنند.
حاشیه نویسی موجودیت نامگذاری شده (Named Entity Annotation (NER))
هدف حاشیه نویسی NER شناسایی و طبقه بندی موجودیتهای نامگذاری شده یا از پیش تعریف شده و یا عبارات خاص در یک جمله است. این ابزار برای جستجوی کلمات بر اساس معنی آنها مانند نام افراد، مکانها و غیره استفاده میشود. NER در استخراج اطلاعات در کنار طبقه بندی و گروهبندی آنها مفید است.
حاشیه نویسی معنایی (Semantic Annotation)
حاشیه نویسی معنایی، اطلاعات متادیتا و اضافی یا برچسبها را به متن اضافه میکند که شامل مفاهیم و موجودیتها مانند افراد، مکانها یا موضوعات است.
حاشیه نویسی خودکار دادهها در برابر حاشیه نویسی انسانی
با گذشت چند ساعت، حاشیه نویسان انسانی خسته میشوند و تمرکز آنها کمتر میشود که اغلب منجر به عملکرد ضعیف و خطا میشود. حاشیه نویسی دادهها وظیفهای که تمرکز کامل پرسنل ماهر را میطلبد و حاشیه نویسی دستی این فرآیند را زمانبر و پرهزینه میکند. به همین دلیل است که تیمهای پیشرو یادگیری ماشین روی برچسب گذاری خودکار دادهها شرط بندی میکنند.
هنگامی که تسک حاشیه نویسی مشخص شد، یک مدل یادگیری ماشین آموزش دیده را میتوان روی مجموعهای از دادههای بدون برچسب اعمال کرد. سپس مدل میتواند برچسبهای مناسب برای مجموعه دادههای جدید و دیده نشده را پیش بینی کند.
برای این منظور میتوانید از ابزار حاشیه نویسی v1 استفاده کنید:
https://www.v7labs.com/get-started
همچنین این ابزار بیش از 500 دیتاست رایگان در اختیار شما قرار میدهد که از طریق لینک زیر میتوانید به آن دسترسی پیدا کنید. این دیتاستها در حوزههای مختلف هستند.:
دوره های مرتبط

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین

پردازش تصویر(فصل اول): مباحث مقدماتی،آستانه گذاری تصویر،تبدیلات شدت روشنایی و هندسی
دیدگاه ها