ساخت dataloader سفارشی با کمک DataLoader و Dataset پایتورچ
در پروژه های یادگیری ماشین، مخصوصا یادگیری عمیق، ما با حجم بسیار بالای داده (big data) روبرو هستیم. و هندل کردن چنین داده ای جهت آموزش یک شبکه عصبی میتواند بسیار سخت و پیچیده باشد. از طرفی کدهای مربوط به پردازش نمونهها و آموزش شبکه عصبی هم میتواند بسیار شلوغ باشد. ما به طور ایده آل دوست داریم، که کد مربوط به آموزش مدل، با کد مربوط به داده جدا باشد تا یک کد خوانا و مدولار داشته باشیم. پایتورچ برای حل این مسئله دو تا کلاس به اسم Dataset و DataLoader دارد که کار با داده را بسیار ساده و راحت میکنند. در این پست میخواهیم با Dataset و DataLoader آشنا شویم و در آخر هم توضیح میدهیم که چطور میتوان یک DataLoader اختصاصی برای داده خود با کمک ابزار PyTorch بسازیم.
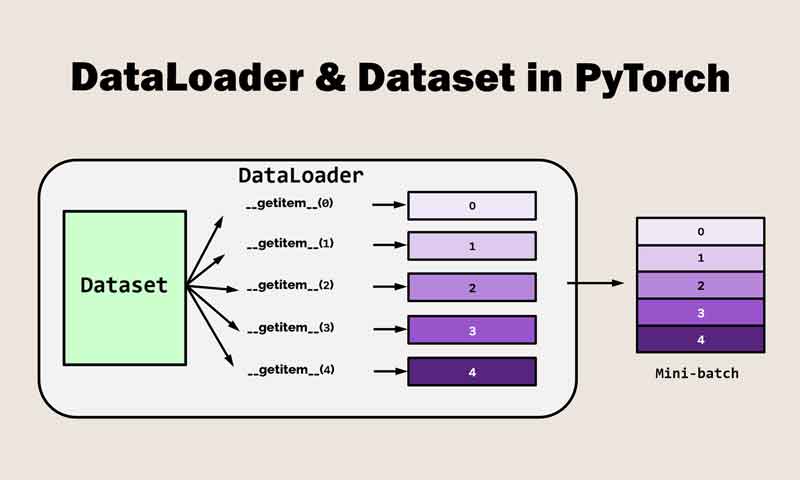
در کتابخانه Pytorch.utils.data دو کلاس به اسم Dataset و DataLoader وجود دارد که کار با داده را بسیار ساده میکنند. به طور کلی Dataset یک نمونه از داده و لیبل متناظر با آن را در خود ذخیره میکند و DataLoader یک حلقه دور داده می پیچد و با کمک آن امکان دسترسی ساده به sample ها را فراهم میکند. DataLoader برای لود کردن داده از یک Dataset و ساخت minibatch استفاده می شود.
کلاس Dataset در پایتورچ
Dataset یک کلاس abstract هست. یعنی یک نقشه (blueprint) برای سایر کلاسها است. ما با کمک ارث بری برنامه نویسی شئی گرای پایتون، از روی کلاسDataset، کلاس مخصوص لود کردن داده خود را تعریف میکنیم.
نکته: به کلاسی که شامل یک یا چندین متد abstract باشد، کلاس abstract گفته میشود، و به متدی که تعریف شده ولی پیادهسازی نشده هم متد abstract گفته میشود.
Python
class CustomDataset(Dataset): def __init__(self,<arguments>): pass def __len__(self): pass def __getitem__(self, index): pass
کلاس Dataset مسئول لود کردن داده (فقط یک سمپل از داده) از یک منبع و پیش پردازش، و تبدیل داده به تنسور است.
کلاس Dataset شامل سه متد اصلی است:
- متد جادویی __init__
- در این متد، آمادهسازی جهت خواندن داده انجام میشه و یه سری شناسه های مرتبط جهت خواندن و تبدیلات داده تعریف میشود.
- متد جادویی __len__
- این متد تعداد نمونه های داده را بر میگرداند
- متد جادویی __getitem__
- این متد، اندیس داده را دریافت کرده و اون داده و به همراه لیبل را خوانده، پیش پردازشهای لازم رو انجام داده و در خروجی قرار میدهد.
- این متد توسط DataLoader جهت پیش پردازش و لود کردن داده استفاده می شود.
کلاس DataLoader در پایتورچ
کلاس DataLoader پایتورچ، یک کلاس utility است و برای لود کردن داده از یک دیتاست و ساخت minibatch جهت آموزش شبکههای عصبی استفاده میشود. کلاس DataLoader بر روی کلاس Dataset ساخته شده است که یک رابط استاندارد برای دسترسی داده فراهم میکند. کلاس DataLoader یک object از کلاس Dataset دریافت میکند و یک راهی فراهم میکند تا بتوان روی داده به صورت batchدسترسی پیدا کرد و داده را به چندین batch تقسیم کند و آماده ارائه آن به شبکه عصبی جهت آموزش بکند.
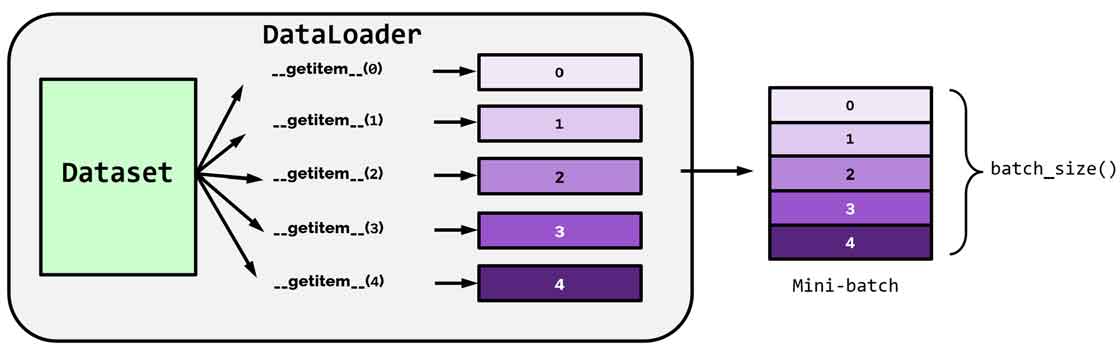
کلاس DataLoader مسئول batching داده و آماده کردن آن به فرمت مناسب جهت به ارائه به شبکه عصبی است.
کلاس DataLoader برای هندل کردن دادههای بزرگ، data augmentation، shuffling و سایر تسکهای پیش پردازش طراحی شده است.
مزایای استفاده از DataLoader
- Efficient data loading: به کاربر اجازه میدهد تا داده را به صورت موازی لود کند.
- Data augmentation: به کاربر اجازه میدهد تا قبل اعمال داده به شبکه ی عصبی، یه سری تبدیلاتی روی داده اعمال کند.
- flexibility: بسیار منعطف است و میتوان با کمک آن فرمتها و منابع مختلف داده را هندل کرد. میتوان با کمکش داده از فایلهای خارجی را بارگذاری کرد و همچنین پیش پردازشها سفارشی روی داده اعمال کرد.
- Shuffling: به کاربر اجازه میدهد که درهر تکرار آموزش شبکه عصبی داده را shuffle کرد. با این کار از overfitting شبکه جلوگیری میکند و خاصیت عمومیت (generalization) شبکه را بهبود میدهد.
فرض کنید یک داده ای به اسم dataset داریم، که داخل اون تعدادی فایل تکست داریم و میخواهیم با کمک Dataset و DataLoader یک دیتالودر سفارشی برای این داده بسازیم.

اول یک کلاس برای لود کردن تنها یک نمونه با کمک Dataset میسازیم. سپس با کمک DataLoader داده را batching میکنیم.
مرحله اول: وارد کردن کتابخانه های مورد نیاز پایتون
Python
import torch import glob import pandas as pd from torch.utils.data import Dataset,DataLoader
مرحله دوم: ساخت کلاس سفارشی برای لود کردن نمونه ها
Python
class CustomDataset(Dataset): def __init__(self,pathname): self.file_names= glob.glob(pathname+ '\*\*.txt') self.class_map= {'S':0,'Z':1}
در این متد، اسم فایلهای تسکت را با کمک تابع glob مشخص میکنیم تا در متد getitem از اونا برای خواندن فایلها استفاده کنیم.
همچنین مشخص کردیم که نمونه های داخل فایل S لیبل 0 و نمونه های داخل Z هم لیبل یک بگیرند.
شما هم بهتر هست فایلهای هر کلاس را داخل یک فولدر بسازید و طبق روال ما، برای آنها یک نقشه لیبل تعریف کنید تا موقع خوندن نمونه ها یک لیبل مناسب برای آنها در نظر بگیرد.
Python
def __len__(self): len(self.file_names)
همونطور که قبلا اشاره کردیم، این متد باید تعداد کل نمونه های داده را برگرداند. از آنجا که اسم همه فایلها به صورت یک لیست داخل شناسه file_names است، برای همین طول این لیست را برمیگردانیم.
Python
def __getitem__(self,indx): filename= self.file_names[indx] df= pd.read_csv(filename,header=None) sample= df.iloc[:,0].to_numpy() sample= torch.from_numpy(sample).type(torch.float32) chr= filename.split('\\')[-1][0] label= self.class_map[chr] return sample,label
در این متد هم، هر بار یک نمونه از داده (نمونه ای که کاربر به index مشخص میکند) با کمک کتابخانه پانداس خوانده میشود، و به تنسور تبدیل میشود. همچنین بسته به اینکه از کدام فایل خوانده شده، طبق نقشه لیبل، لیبل آن ساخته شده و همراه با سمپل به خروجی داده می شود.
خب ما تا اینجای کار تونستیم یک کلاس برای ساخت Dataset سفارشی بسازیم. در ادامه باید از روی این کلاس یک object بسازیم.
مرحله سوم: ساخت Object از روی کلاس تعریف شده
Python
ds= CustomDataset('dataset')
حال اگر به صفحه متغیرها نگاه کنیم، میبینم که object از نوع CustonDataset ساخته شده که داخلش 200 فایل هست.

ما با کمک این کلاس، همانند زیر فقط میتوانیم در هر لحظه یک نمونه از داده را بخوانیم.
Python
Index=0 sample,label= ds[index]
برای مثال در این کد، ما اولین نمونه از داده را خواندیم و در دو متغیر sample, label داده ورودی و لیبل آنرا قرار دادیم.
اما مسئه این است که ما میخواهیم داده را batch بندی کنیم و در داخل هر تکه، چندین نمونه را داشته باشیم. این وظیفه DataLoader هست که در ادامه توضیح میدهیم که چطور میتوان اینکار را انجام داد.
مرحله چهارم: Batching داده با استفاده از DataLoader
حال این object آماده هست تا بدیم به DataLoader، تا داده را batchبندی کند.
Python
data_loader= DataLoader(ds,batch_size=32,shuffle=True)
- ds همان objectی است که که از روی کلاس Dataset ساختیم.
- batch_size مشخص میکند که در هر تکه چندین نمونه قرار بگیرید که ما اینجا، 32 در نظر گرفتیم.
- Shuffle هم مشخص میکند که در هر تکرار آموزش شبکه عصبی، آیا ترتیب داده ها به صورت تصادفی تغییر کند یا نه. که ما True گذاشته ایم تا ترتیب تغییر کنه و از احتمال overfitting شبکه جلوگیری کند.
مرحله پنجم: ایجاد یک حلقه جهت دستری به batchها
حال اگر بخواهیم به هر تکه دسترسی داشته باشیم، یک حلقه مینویسیم و در هر تکرار یک تکه از داده را جدا کرده و به شبکه عصبی اعمال میکنیم تا آموزش ببیند.
Python
for x_batch,y_batch in data_loader: print(x_batch.shape,y_batch.shape) >>> torch.Size([32, 4097]) torch.Size([32]) torch.Size([32, 4097]) torch.Size([32]) torch.Size([32, 4097]) torch.Size([32]) torch.Size([32, 4097]) torch.Size([32]) torch.Size([32, 4097]) torch.Size([32]) torch.Size([32, 4097]) torch.Size([32]) torch.Size([8, 4097]) torch.Size([8])
ما در این کد فقط اندازه هر تکه و لیبلهاش را چاپ کردیم. شما در عمل باید این تکه و لیبلهاش رو به شبکه ارائه بدهید.
در دوره تخصصی و پروژه محور پایتورچ مباحث مرتبط با ساخت dataloader سفارشی برای داده های مختلف را کامل آموزش داده ایم.
ما در دوره پایتورچ سه هدف اصلی داریم:
- یادگیری تئوری ریاضیات شبکه های عصبی و روشهای بهینه سازی
- یادگیری کار با ابزار پایتورچ به صورت تخصصی
- ساخت dataloader ها اختصاصی برای داده های خودمان
- پیادهسازی شبکه های عصبی با ابزار پایتورچ
- انجام پروژه های عملی
دوره های مرتبط

دوره پردازش سیگنال قلبی ECG

پردازش سیگنال مغزی با کتابخانه MNE پایتون

پیادهسازی شبکه های عصبی با پایتورچ PyTorch

برنامه نویسی شیء گرا در پایتون Python

کتابخانه NumPy و matplotlib در پایتون

دیدگاه ها