
مدل CNN-RNN برای تولید کپشن تصاویر
- دسته:اخبار علمی
- هما کاشفی
ما انسان ها به راحتی می توانیم توصیفی برای تصاویر تولید کنیم. اما ماشین چطور می تواند برای تصاویری که به عنوان ورودی دریافت می کند توصیف تولید کند؟ به لطف پیشرفت های حاصل در حوزه های بینایی ماشین و یادگیری عمیق و همچنین در دسترس بودن دیتاست های گسترده به راحتی می توان برای هر نوع تصویری با استفاده از دو نوع از مهم ترین شبکه های عمیق کپشن تولید کرد. در این پست این مدل CNN-RNN را به اختصار معرفی خواهیم کرد.
ساختار کلی مدل CNN-RNN
این مدل یک شبکه CNN است که روی ناحیه تصویر اعمال میشود و پس از آن یک RNN قرار میگیرد که از ورودی شبکه قبلی استفاده میکند. این شبکه RNN در نهایت میتواند توضیحات جدیدی از نواحی تصویر ایجاد کند. در نتیجه دو مدل با هم ترکیب میشوند که برای برچسب گذاری تصاویر با جملات استفاده میشود. در شکل زیر معماری مدل نشان داده شده است. ماژول اول یک شبکه VGG است و ماژول دوم یک شبکه RNN است.
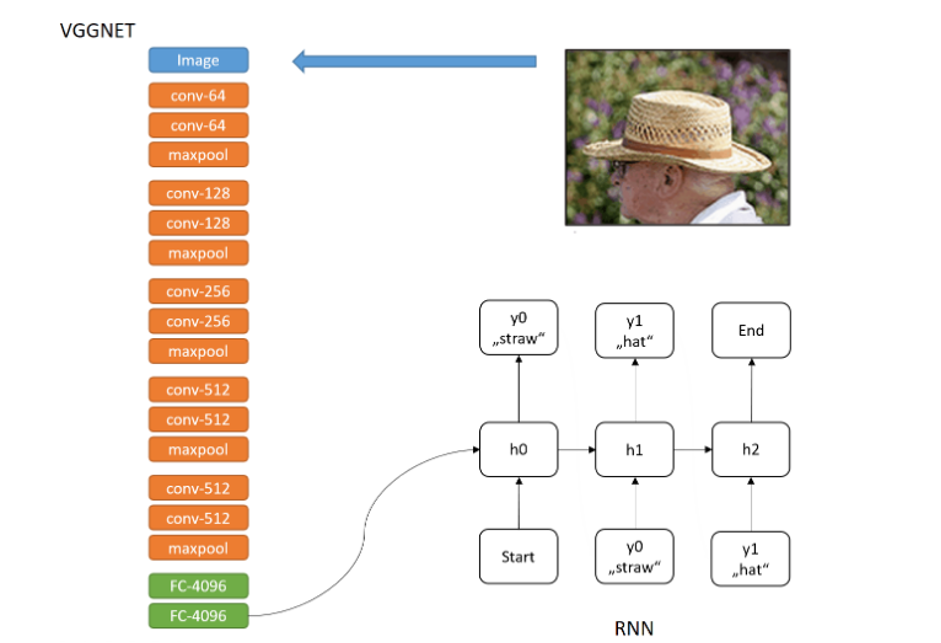
این تصویر معماری RNN-CNN را نشان میدهد. در این مورد یک CNN استفاده شده و پس از آن RNN است که برای برچسب گذاری تصویر با یک جمله استفاده میشود
نمونههایی از خروجی
به طور کلی، شبکه توصیف بسیار دقیق و معقولی از تصاویر تولید میکند. نمونههایی از تصاویر تولید شده با توضیحات متنی در شکل زیر نشان داده شدهاند. در این مثالها شبکه به خوبی کار کرده است به جز دو مورد آخر که wakeboard و two young girls اشتباه نوشته شدهاند. جالب توجه است که توصیف اول “mans in black shirt is playing guitar” در مجموعهی آموزش وجود ندارد. اما “man in black shirt” بیست بار در مجموعهی آموزش وجود دارد و “is playing guitar” شصت بار در مجموعهی آموزش رخ داده است. بنابراین شبکه یاد خواهد گرفت که چطور این عبارات را با هم ترکیب کند و یک نتیجهی معنادار تولید کند. اگرچه این نتایج بسیار چشمگیر به نظر میرسند اما شبکه دارای محدودیتهایی هست. برای مثال مدل تنها میتواند یک آرایه خاص از پیکسلها با رزولوشن ثابت را پردازش کند. علاوه بر این این مفهوم مبتنی بر دو شبکهی مجزاست. در مقالات جدیدتر به حل این چالش ها پرداخته شده است.

خروجی مدل Image Captioning
در دوره ی جامع و پروژه محور شبکههای عصبی بازگشتی این پروژهی Image Captioning به طور کامل پیاده سازی شده است.
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دیدگاه ها