به تصویر کشیدن آن چیزی که Convnetها یاد میگیرند
- دسته:اخبار علمی
- هما کاشفی
بازنمایی ویژگیهایی که توسط convnetها آموخته میشوندتا حد زیادی قابل تجسم هستند به این دلیل که آنها بازنمایی مفاهیم بصری هستند.
از سال 2013، تکنیکهای زیادی برای تجسم سازی و تفسیر این بازنماییها ایجاد شده است. همهی آنها را اینجا بررسی نمیکنیم. یک مورد آن را مورد تمرکز قرار میدهیم که
تجسم خروجیهای Convnet میانی (فعالسازیهای میانی) هستند و برای درک آن مفیدند که چگونه لایههای Convnet متوالی، ورودی خود را تغییر میدهند و به این ترتیب میتوان اولین ایده از معنای فیلترهای Convnet جداگانه را بدست آورد
تجسم سازی فعالسازیهای میانی
تجسم فعالسازیهای میانی شامل feature map هایی است که خروجی چندین لایهی کانولوشن و pooling در یک شبکه هستند (خروجی یک لایه activation نامیده میشود). این تجسم سازی دیدی به دست میدهد که چگونه یک ورودی به فیلترهای مختلفی که توسط شبکه آموخته شده است تجزیه میشود. شما میخواهید feature map های با سه بعد را تجسم کنید: عرض، ارتفاع و عمق (تعداد کانال). هر کانال، ویژگیهای نسبتاً مستقل را رمزگذاری میکند و بنابراین راه مناسبی برای تجسم این feature mapها، ترسیم محتویات هر کانال به صورت تصویر دوبعدی است. فرض کنید مدلی که قبلاً روی دیتاست dogs-vs-cats آموزش دیده را داریم و آن را دوباره بارگذاری میکنیم:
from keras.models import load_model
model = load_model(‘cats_and_dogs_small_2.h5’)
model.summary()
و معماری مدل به شکل زیر است:


حال یک تصویر ورودی (تصویری از یک سگ) را در نظر میگیریم و آن را پیش پردازش میکنیم:
img_path = ‘/Users/fchollet/Downloads/cats_and_dogs_small/test/cats/cat.1700.jpg’
from keras.preprocessing import image
import numpy as np
img = image.load_img(img_path, target_size=(150, 150))
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor, axis=0)
img_tensor /= 255
حال با استفاده از کد زیر، تصویر را نمایش میدهیم:
import matplotlib.pyplot as plt
plt.imshow(img_tensor[0])
plt.show()

به منظور استخراج feature mapهایی که میخواهید ببینید، یک مدل Keras ایجاد کردهاید که دستههایی از تصاویر را به عنوان ورودی میگیرد و خروجی آن فعالسازی تمام لایههای کانولوشن و pooling است. برای انجام این کار از Model کراس استفاده میکنید. یک مدل در کراس با دو آرگمان مقداردهی میشود: تنسور ورودی (لیستی از تنسورهای ورودی) و تنسور خروجی (لیستی از تنسورهای خروجی). کلاس نتیجه یک مدل Keras است درست مانند مدلهای Sequential که با آنها آشنا هستید و ورودیهای خاص را به خروجی مشخص تبدیل میکند.
from keras import models
layer_outputs = [layer.output for layer in model.layers[:8]]
activation_model = models.Model(inputs=model.input, outputs=layer_outputs)
هنگامی که یک ورودی به مدل داده میشود، مدل مقادیر فعالسازی لایه را در مدل اصلی برمیگرداند. به طور کلی، یک مدل میتواند هر تعداد ورودی و خروجی داشته باشد. این مدل، یک ورودی و هشت خروجی دارد: یک خروجی در هر فعالسازی لایه
activations = activation_model.predict(img_tensor)
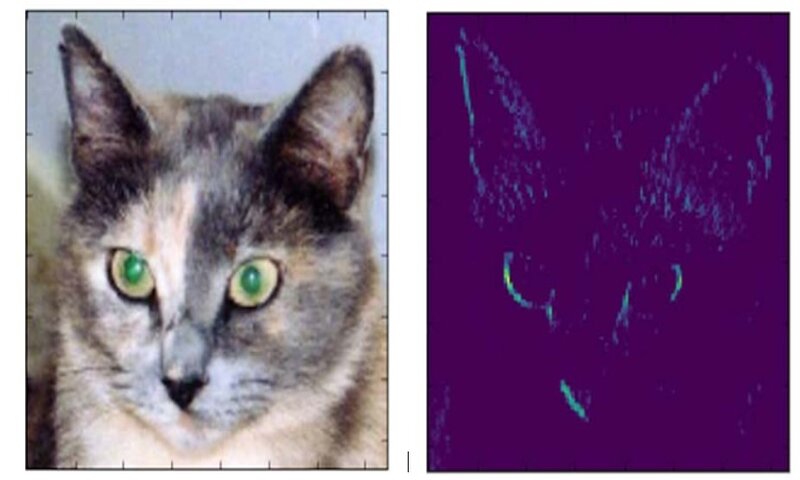
برای مثال، این فعالسازی اولین لایهی کانولوشنی برای ورودی تصویر گربه است:
first_layer_activation = activations[0]
print(first_layer_activation.shape)
(1, 148, 148, 32)
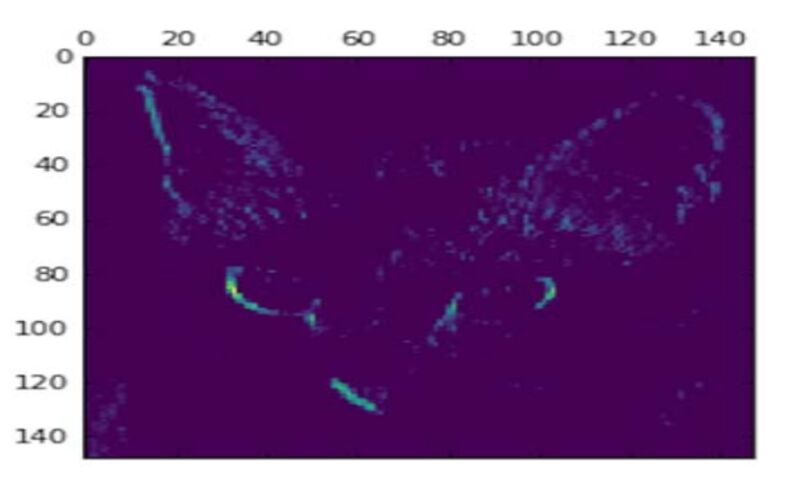
به نظر میرسد که این کانال، تشخیص دهندهی لبههای مورب بوده است. حال اگر بخواهیم هفتمین کانال را رسم کنیم، داریم:
plt.matshow(first_layer_activation[0, :, :, 7], cmap=’viridis’)

این لایه، آشکارساز «نقاط سبز روشن» است که برای رمزگذاری چشم گربه مفید است. در این مرحله بیایید یک تجسم کامل از تمام فعالسازیها در شبکه رسم کنیم. هر کانال در هر یک از هشت feature map را میتوان استخراج کرد و رسم کرد و نتایج را در یک تنسور تصویر بزرگ و کانالهایی که در کنار هم قرار گرفتهاند نمایش میدهیم.
کد آن به صورت زیر است:

و خروجی آن به صورت زیر است:
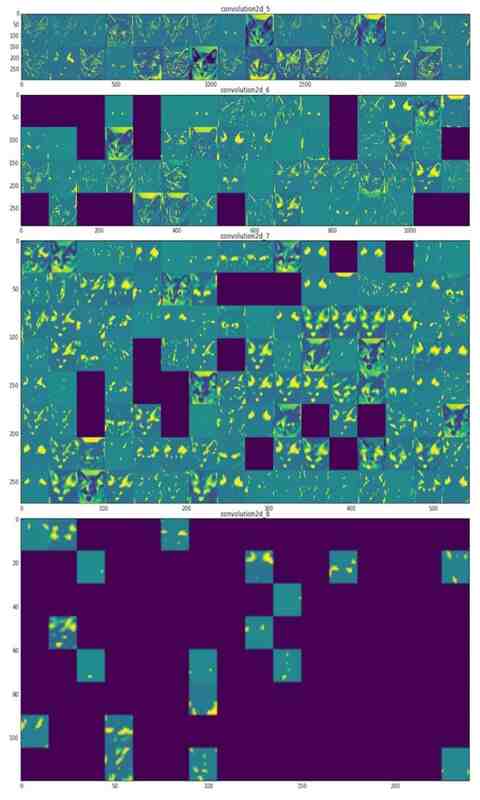
در اینجا چندین نکته قابل توجه است:
-اولین لایه به عنوان مجموعهای از آشکارسازهای مختلف لبه عمل میکند. در آن مرحله، فعالسازیها تقریباً تمام اطلاعات موجود در تصویر اولیه را حفظ میکنند.
-هرچقدر بالاتر میروید؛ فعالسازیها به طور فزایندهای انتزاعیتر میشوند و از نظر بصری قابلیت تفسیر کمتری دارند. آنها کم کم شروع به رمزکذاری مفاهیم سطح بالاتری مانند «گوش گربه» و «چشم گربه» میکنند. بازنماییهای بالاتر حاوی اطلاعات کمتری در مورد محتوای بصری تصویر و اطلاعات بیشتری در مورد کلاس تصویر هستند.
-پراکندگی فعالسازیها با عمق لایه افزایش مییابد: در لایه اول، تمام فیلترها توسط تصویر ورودی فعال میشوند اما در لایههای بعدی، فیلترهای بیشتری خالی هستند. این بدان معناست که الگوی رمزگذاری شده توسط فیلتر در تصویر ورودی یافت نمیشود.
تا به اینجا یک ویژگی مهم بازنماییهایی که توسط شبکههای عصبی عمیق آموخته شده است را اثبات کردهایم: ویژگیهای استخراج شده توسط یک لایه با افزایش عمق لایه به طور فزایندهای انتزاعیتر میشوند. فعالسازیهای لایههای بالاتر، اطلاعات کمتر و کمتری در مورد ورودی خاص دارند و اطلاعات بیشتر و بیشتری در مورد هدف (در این دیتاست، کلاس تصویر: گربه یا سگ) دارند. یک شبکه عصبی عمیق به طور موثر به عنوان یک خط لوله تقطیر اطلاعات با دادههای خام است (در این مورد، تصاویر RGB) و به طور مکرر تغییر شکل میدهد تا اطلاعات نامربوط فیلتر شوند (مثلاً ظاهر خاص تصویر) و اطلاعات مفید، بزرگنمایی و پالایش شوند (برای مثال کلاس تصویر).
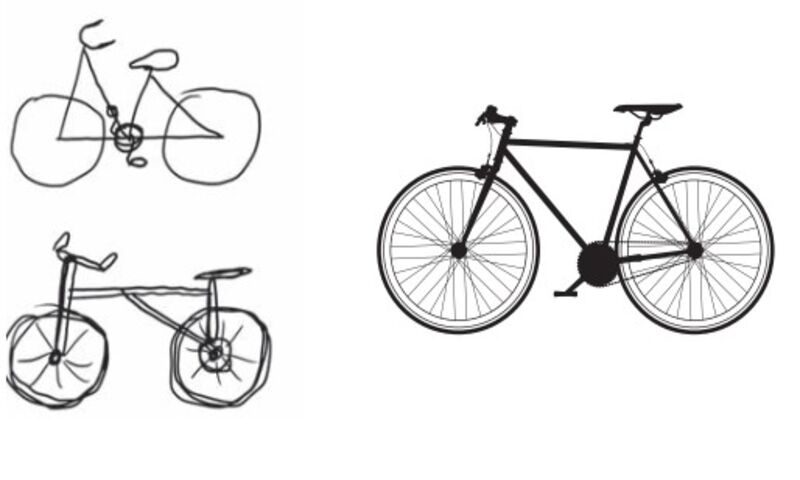
این مشابه نحوهی درک انسانها و حیوانات از جهان است: پس از مشاهده یک صحنه به مدت چند ثانیه، انسان میتواند به یاد بیاورد که کدام اشیا انتزاعی در صحنه وجود داشتند (دوچرخه، درخت) اما نمیتواند ظاهر خاص این اشیا را به خاطر بیاورد. در واقع اگر سعی کردهاید که شکل یک دوچرخه معمول را از حافظهی خود ترسیم کنید، به احتمال زیاد حتی با وجود اینکه هزاران دوچرخه در طول زندگی خود دیدهاید نمیتوانید تصویر مناسبی از آن را رسم کنید. همین حالا امتحان کنید: این اثر کاملاً واقعی است. مغز شما یاد گرفته است که ورودی بصری خود را کاملاً انتزاعی کند (تبدیل تصویر به مفاهیم بصری سطح بالا در حالی که جزئیات بصری نامربوط را فیلتر کند) و به همین دلیل به خاطر سپردن چیزهایی که در اطراف خود میبینید بسیار دشوار میشود.
در سمت چپ تصویر زیرا تلاشهایی برای رسم یک دوچرخه با حافظه را نشان میدهد و سمت راست شماتیک دوچرخهی واقعی است.
منبع: Deep Learning with Python (Francois Chollet)
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دیدگاه ها