بررسی عیب قانون یادگیری پس انتشار خطا(Back propagation)
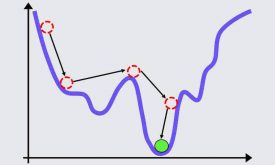
در جلسه چهارم تئوری الگوریتم معروف پس انتشار خطا را آموزش داده در متلب به صورت مرحله به مرحله پیادهسازی کرده و چندین پروژه عملی از جلمه تشخیص سرطان سینه (پروژه عملی طبقهبندی) و پیش بینی میزان آلودگی هوا (پروژه عملی رگرسیون) با استفاده از شبکه عصبی پرسپترون چندلایه به صورت گام به گام در متلب پیادهسازی کردیم. الگوریتم پس انتشار خطا همانند LMS از گرادیان نزولی برای تنظیم وزنهای سیناپسی استفاده میکند. الگوریتم گرادیان نزولی در جهت شیب منفی خطا با یک گامی(نرخ یادگیری) حرکت میکند تا به مقدار بهینه برسد. مقدار بهینه جایی است که شیب خطا صفر شود. در حالت ایده آل با تعیین یک نرخ یادگیری مناسب میتوان به خطای حداقل رسید. ولی در پروژههای عملی تعیین نرخ یادگیری بسیار سخت و چالش برانگیز است، زیرا که اگه نرخ یادگیری کم انتخاب شود، الگوریتم ممکن است در مینیممهای محلی گیر کند (زیرا که مینیمم محلی خواصی شبیه به مینیمم اصلی دارند و در این مناطق نیز شیب خطا صفر است و الگوریتم به اشتباه فکر میکند که به مقدار بهینه رسیده است) و در نتیجه شبکه به درستی آموزش نمیبیند و یا اگر نرخ یادگیری بزرگ انتخاب شود امکان دارد شبکه به حالت نوسانی و ناپایدار برسد و در نتیجه همگرا نشده و آموزش نبیند. در این جلسه چالشهای تعیین نرخ یادگیری را توضیح میدهیم و در ادامه چند روش ساده از قبیل ترم ممنتوم، search then converge و time variant را برای حل این مسئله طبق مطالب کتاب ارائه میدهیم و در متلب پیادهسازی میکنیم و مزایا و معایب هر روش را توضیح میدهیم و در انتها توضیح میدهیم که روشهای ذکر شده با اینکه تا حدودی توانستهاند مشکل تعیین نرخ یادگیری را حل کنند ولی کافی نیستند و نیاز است که شرطهای دیگری نیز در تعیین نرخ یادگیری گنجانده شود.
برای درک بهتر مطالب ما در این جلسه نیز چندین مثال و پروژه عملی در متلب انجام دادهایم.
ویدئوی زیر بخش کوتاهی از جلسهی پنجم است که برای آشنایی در اختیار شما قرار داده شده است. بخش کامل این جلسه، و همچنین پکیج کامل شبکههای عصبی (شامل تمام جلسات) را از لینکهای زیر خریداری نمایید.
باتشکر
خرید جلسهی پنجم
خرید کامل پکیج شبکههای عصبی
دوره های مرتبط
شبکه عصبی ELM (جلسه نهم)
شبکه عصبی RBF(جلسه هشتم)
mlp با قانون یادگیری دلتا بار دلتا (جلسه هفتم)

MLP با قانون یادگیری دلتا دلتا (جلسه ششم)
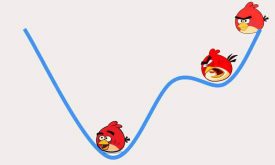
تعیین نرخ یادگیری پس انتشار خطا (جلسه پنجم)

شبکه عصبی پرسپترون چندلایه (جلسه چهارم)
دیدگاه ها