بینایی ماشین
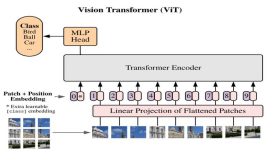

نحوهی کار Vision Transformer (ViT)
مدل ViT (Vision transformer) یک مدل شبیه به transformer است که برای انجام تسکهای پردازش بینایی طراحی شده است. در این مقاله می آموزیم که این مدل چگونه کار میکند.
معرفی مدل Segment Anything: اولین مدل پایه برای سگمنتبندی تصویر
سگمنت بندی (Segmentation) به معنی شناسایی پیکسلهای تصویر متعلق به یک شی است و یکی از تسکهای اصلی در بینایی ماشین است و در طیف گستردهای از برنامهها استفاده میشود از تحلیل تصاویر علمی گرفته تا ویرایش تصاویر. اما ایجاد…