معرفی لایهی Separable Convolution
- دسته:اخبار علمی
- هما کاشفی
هرکسی که نگاهی به معماری شبکه MobileNet بیندازد، با مفهوم separable convolution روبرو خواهد شد. اما این لایه چیست و چه تفاوتی با لایهی کانولوشن معمولی دارد؟
دو نوع لایهی separable convolution وجود دارند: نوع اول spatial separable convolutions است و نوع دوم depthwise separable convolution است.
Spatial Separable Convolutions
از نظر مفهومی این لایه سادهتر است و ایدهی اصلی آن جداسازی یک کانولوشن به دو کانولوشن است، پس با آن شروع میکنیم. متأسفانه spatial separable convolutions محدودیتهای قابل توجهی دارند و در یادگیری عمیق زیاد مورد استفاده قرار نمیگیرند. دلیل نامگذاری spatial separable convolution آن است که با ابعاد فضایی تصویر و کرنل سر و کار دارد: یعنی عرض و ارتفاع. (بعد دیگر، بعد «عمق» است که تعداد کانالهای هر تصویر است).
یک لایهی spatial separable convolution یک کرنل را به دو کرنل کوچکتر تقسیم میکند. رایجترین مورد استفادهی آن تقسیم یک کرنل 3*3 به دو کرنل 3*1 و 1*3 است، مانند شکل زیر:
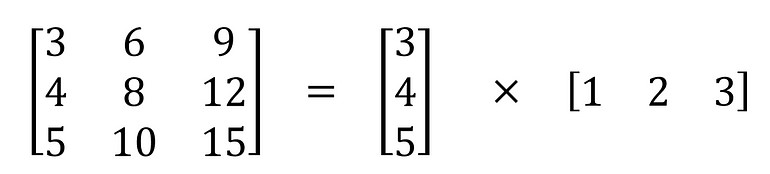
حال به جای آنکه یک عملیات کانولوشن با 9 ضرب انجام دهیم، دو عملیات کانولوشن انجام میدهیم که هر یک 3 ضرب دارند (در مجموع 6 ضرب) تا در نهایت به همان نتیجه برسیم. با ضرب کمتر، پیچیدگی محاسباتی کاهش مییابد و شبکه سریعتر اجرا میشود.
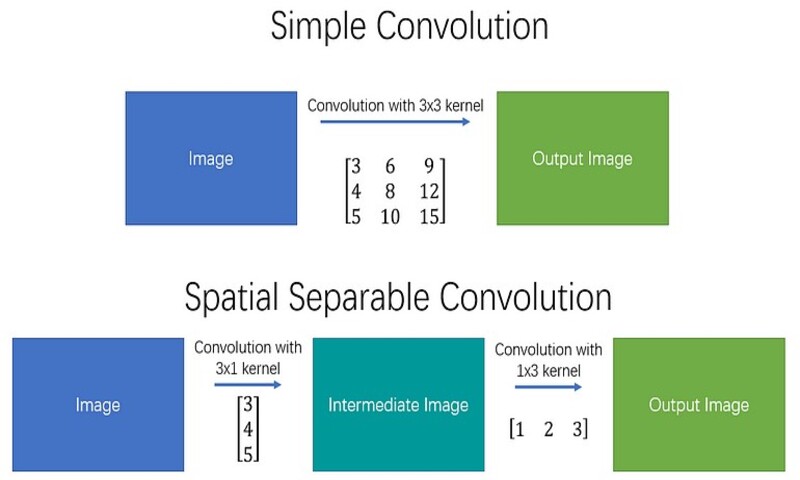
یکی از معروفترین کانولوشنهایی که میتوان به صورت فضایی جدا کرد کرنل Sobel است که برای تشخیص لبههای تصویر استفاده میشود:
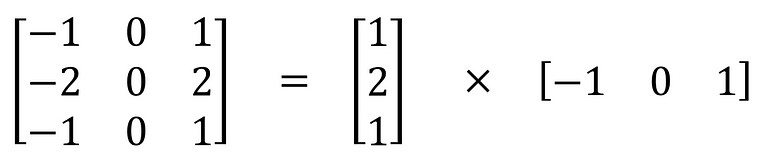
مشکل اصلی spatial separable convolution آن است که نمیتوان همهی کرنلها را به دو کرنل کوچکتر تقسیم کرد. این مشکل به ویژه در طول روند آموزش آزاردهنده میشود، زیرا از بین تمام کرنلهای ممکن که شبکه میتواند استفاده کند، تنها بخش کوچکی از آنها را میتواند به دو کرنل کوچکتر جدا کند.
Depthwise Separable Convolutions
برخلاف کانولوشن قبلی، لایههای کانولوشن Depthwise separable با کرنلهایی کار میکنند که نمیتوان آنها را به دو کرنل کوچکتر تقسیم کرد. از این رو Depthwise Separable Convolution بیشتر مورد استفاده قرار میگیرد. این لایه در کراس به صورت keras.layers.SeparableConv2D قابل دسترسی است.
کانولوشن depthwise separable به این دلیل نامگذاری شده است که نه تنها با ابعاد فضایی سرو کار دارد بلکه با بعد عمق نیز سر و کار دارد یعنی تعداد کانالها. یک تصویر ورودی ممکن است سه کانال داشته باشد: RGB. پس از اعمال چند کانولوشن، تصویر ممکن است دارای چندین کانال شود. شما میتوانید هر کانال را تقسیر خاصی از تصویر بدانید؛ برای مثال کانال «قرمز» ویژگی «قرمزبودن» هر پیکسل را تصویر میکند و کانال «آبی» ویژگی «آبی بودن» هر پیکسل را تفسیر میکند و کانال «سبز» ویژگی «سبز بودن» هر پیکسل را تفسیر میکند. یک تصویر با 64 کانال به عبارت دیگر دارای 64 تفسیر از آن تصویر است.
مشابه spatial separable convolution، یک کانولوشن depthwise separable یک کرنل را به دو کرنل مجزا تقسیم میکند که دو کانولوشن انجام میدهد: کانولوشن depthwise و کانولوشن pointwise. اما ابتدا بهتر است ببینیم یک کانولوشن معمولی چه کار میکند.
کانولوشن نرمال:
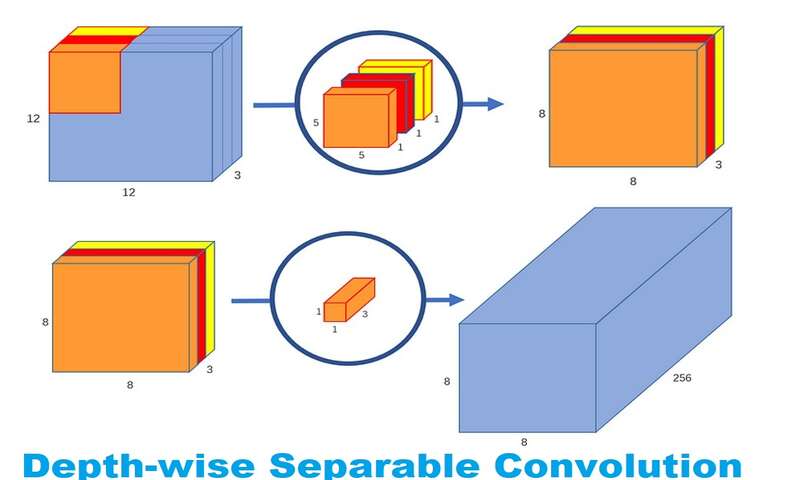
یک تصویر معمولی، دو بعدی نیست. علاوه بر عرض و ارتفاع دارای عمق نیز هست. فرض کنید که یک تصویر ورودی با ابعاد3*12*12 پیکسلی داریم که یک تصویر RGB به سایز 12*12 است.
بیایید یک کانولوشن 5*5 روی یک تصویر بدون padding انجام دهیم و stride یا گام حرکت را نیز 1 در نظر بگیریم. اگر تنها عرض و ارتفاع تصویر را در نظر بگیریم، فرآیند کانولوشن چیزی به این شکل است: 12*12à (5*5)à 8*8. کرنل 5*5 هربار با هر 25 پیکسل، ضرب اسکالر میشود و یک عدد را به عنوان خروجی میدهد. در نهایت با یک تصویر 8*8 پیکسلی، عملیات تمام میشود و هیچ paddingای وجود ندارد (12-5+1=8).
با این حال، از آنجاییکه تصویر سه کانال دارد، کرنل کانولوشن نیز باید 3 کانال داشته باشد. این بدان معنی است که به جای 25 ضرب، در واقع با هر بار حرکت کرنل 5*5*3=27 ضرب انجام میدهیم. درست مانند تفسیر دو بعدی، روی هر 25 پیکسل، ضرب ماتریس اسکالر انجام میدهیم و یک عدد خروجی تولید میکنیم. یک تصویر 3*12*12 پس از آن که از یک کرنل 3*5*5 عبور کرد به یک تصویر 1*8*8 تبدیل میشود.
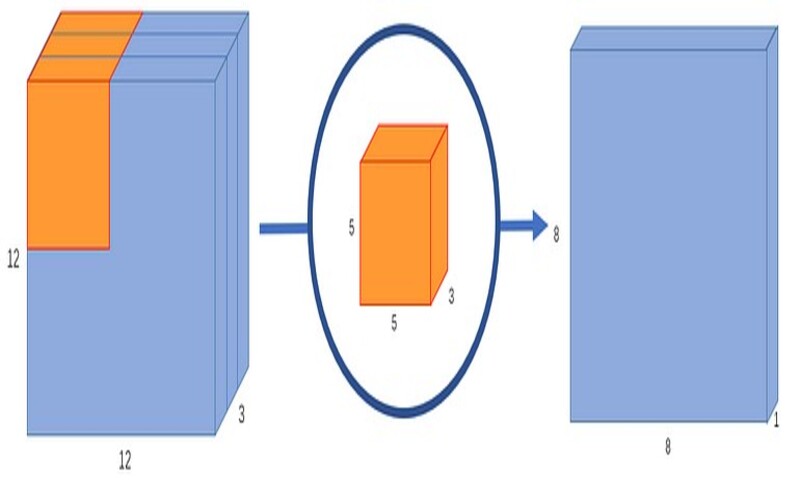
اما اگر بخواهیم تعداد کانالهای تصویر خروجی خود را افزایش دهیم چه؟ اگر خروجی به سایز 256*8*8 بخواهیم چطور؟
خوب میتوانیم 256 کرنل ایجاد کنیم و تا در نهایت 256 تا تصویر 1*8*8 داشته باشیم سپس آنها را روی هم قرار دهیم تا یک خروجی تصویر 256*8*8 تولید کنیم.
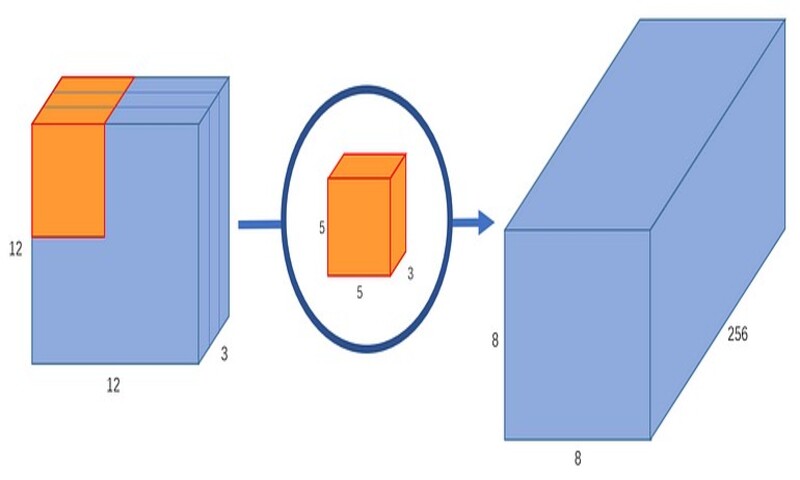
این روند کار کانولوشن معمولی است. اگر آن را مانند یک تابع در نظر بگیریم داریم:
12*12*3 –> (5*5*3*256) –> 12*12*256
( که در 5*5*3*256 به ترتیب اعداد نشاندهندهی ارتفاع، عرض، تعداد کانالهای ورودی و تعداد کانالهای خروجی کرنل هستند). ما کل تصویر را در کرنل ضرب نمیکنیم، بلکه کرنل را در هر بخش از تصویر حرکت میدهیم و قسمتهای کوچک آن را به طور جداگانه در کرنل ضرب میکنیم.
یک لایهی depthwise separable convolution این فرآیند را به دو بخش جدا میکند: یک کانولوشن depthwise و یک کانولوشن pointwise
بخش اول: Depthwise Convolution
در بخش اول، یک تصویر ورودی را به یک لایهی کانولوشن میدهیم بدون اینکه عمق تصویر تغییر کند. این کار را با استفاده از سه کرنل به شکل 1*5*5 انجام میدهیم.
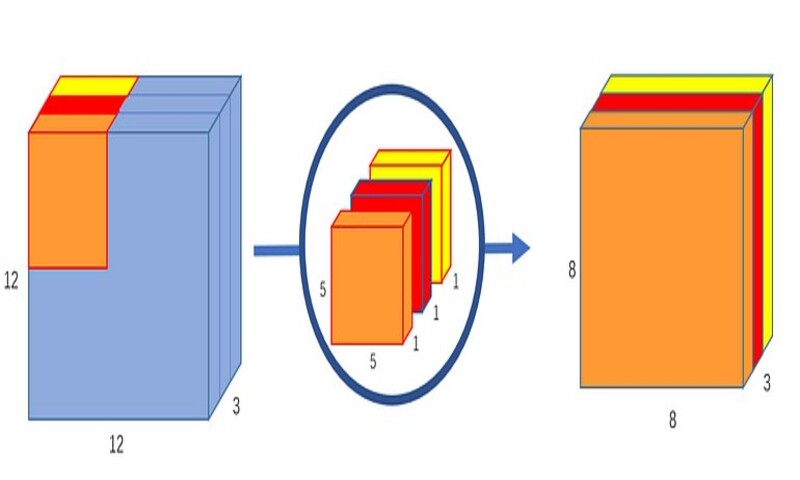
هر کرنل 1*5*5 روی یک کانال از تصویر تکرار میشود (توجه کنید یک کانال نه همهی کانالها) و ضرب اسکالر روی هر گروه 25 پیکسل انجام میشود و یک تصویر 1*8*8 را به دست میدهد. چیدن این تصاویر پشت سر هم به صورت پشته یک تصویر 3*8*8 ایجاد میکند.
بخش دوم: Pointwise Convolution
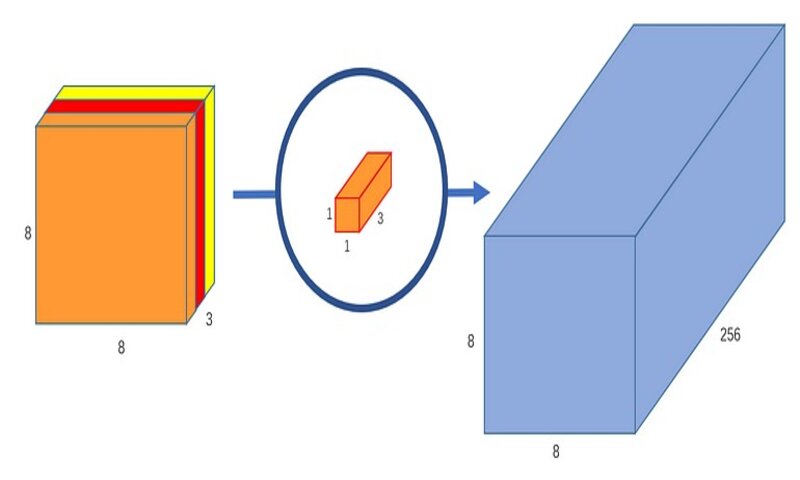
به یاد داشته باشید که کانولوشن نرمال یک تصویر 3*12*12 را به یک تصویر 256*8*8 تبدیل میکند. در حال حاضر، کانولوشن depthwise، تصویر 3*12*12 را به یک تصویر 3*8*8 تبدیل کرده است. حال ما باید تعداد کانالهای هر تصویر را افزایش دهیم.
دلیل نامگذاری pointwise convolution آن است که از یک کرنل 1*1 یا کرنلی استفاده میکند که هر بار روی یک نقطه تکرار میشود. این کرنل عمقی برابر با تعداد کانالهای تصویر ورودی دارد. در مثال ما، 3 است. بنابراین یک کرنل 3*1*1 روی تصویر 3*8*8 تکرار میشود تا در نهایت یک تصویر 1*8*8 بدست آید.
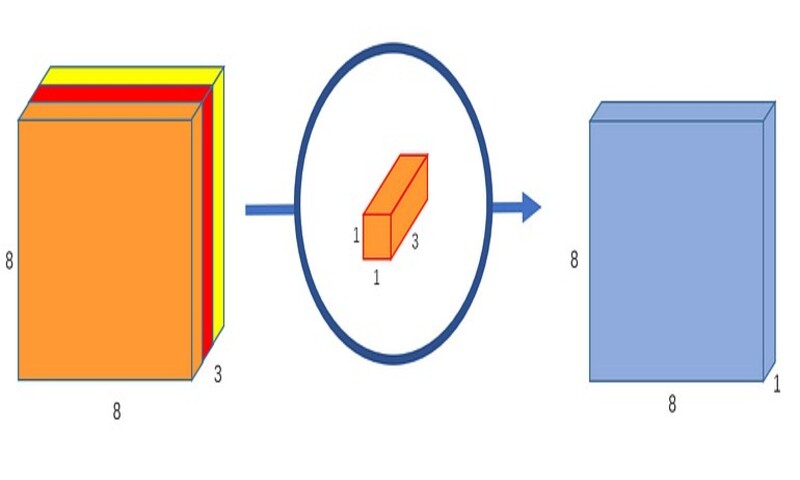
میتوانیم 256 تا کرنل 3*1*1 ایجاد کنیم که خروجی یک تصویر 1*8*8 میدهد و در نهایت تصویری به ابعاد 256*8*8 ایجاد کنیم.
و تمام!
ما کانولوشن را به دو بخش تقسیم کردیم: یک کانولوشن depthwise و یک کانولوشن pointwise. به روش انتزاعتر، اگر تابع کانولوشن اصلی
12*12*3 –> (5*5*3*256) –> 12*12*256 باشد، میتوانیم این کانولوشن جدید را به صورت زیر نشان دهیم:
12*12*3 –> (5*5*1*1) –> (1*1*3*256) –> 12*12*256
خوب، نکتهی ایجاد یک کانولوشن depthwise separable چیست؟
بیایید تعداد عملیات ضرب که کامپیوتر باید در کانولوشن نرمال انجام دهد را محاسبه کنیم. 256 تا کرنل 3*5*5 داریم که 8*8 بار حرکت میکنند. در نهایت 256*3*5*5*8*8 =1228800 عملیات ضرب خواهیم داشت.
در مورد separable convolution چطور؟ در کانولوشن depthwise، ما 3 تا کرنل 1*5*5 داریم که 8*8 بار حرکت میکند. در نهایت 3*5*5*8*8= 4800 ضرب خواهیم داشت. در کانولوشن pointwise، 256 تا کرنل 3*1*1 داریم که 8*8 بار حرکت میکند. 256*1*1*3*8*8 =49152 ضرب خواهیم داشت. اگر آنها را با هم جمع کنیم، 53952 ضرب میشود.
52952 بسیار کمتر از 1228800 است. با محاسبات کمتر شبکه قادر است در مدت زمان کوتاهتری، پردازش بیشتری را انجام دهد.
با این حال این کانولوشنها چطور کار میکنند؟ آیا این دو کانولوشن یک عملیات را انجام نمیدهند؟ در هر دو مورد، تصویر را از یک کرنل 5*5 عبور میدهیم و آن را به یک کانال تقلیل میدهیم و سپس آن را با 256 کانال بسط میدهیم. چطور یک نوع دو برابر دیگری سریعتر است.
پس از مدتی تأمل در مورد آن، متوجه شدم که تفاوت اصلی این است:
در کانولوشن نرمال، ما تصویر اصلی را 256 بار تغییر میدهیم و هر تبدیل 5*5*3*8*8 = 4800 ضرب دارد. در separable convolution ما فقط یکبار واقعاً تصویر را تغییر میدهیم و آن تغییر در depthwise convolution است. سپس تصویر تبدیل شده را میگیریم و آن ر به 256 کانال تبدیل میکنیم. بدون نیاز به تغییر چندین بارهی تصویر، میتوانیم در توان محاسباتی صرفه جویی کنیم.
لازم به ذکر است که هم در keras و هم در Tensorflow، آرگمانی به نام depth multiplier است. در حالت پیش فرض روی یک تنظیم شده است. با تغییر این آرگمان، میتوانیم تعداد کانالهای خروجی را در dpthwise convolution تغییر دهیم. برای مثال اگر این آرگمان را روی 2 تنظیم کنیم، هر کرنل 1*5*5 تصویر خروجی به ابعاد 2*8*8 میدهد و خروجی کلی کانولوشن به صورت 6*8*8 خواهد شد. برخی از افراد ممکن است بخواهند depth multiplier را به صورت دستی تنظیم کنند تا تعداد پارامترها را در شبکهی عصبی خود افزایش دهند و ویژگیهای بیشتری بیاموزند.
آیا depthwise separable convolution معایبی هم دارد؟ قطعاً! از آنجاییکه این لایه تعداد پارامترها را در یک کانولوشن کاهش میدهد، اگر شبکه شما از ابتدا کوچک باشد، ممکن است با پارامترهای بسیار کمی مواجه شوید و شبکه شما در طول آموزش به خوبی یاد نگیرد. با این حال اگر به درستی استفاده شود میتواند بدون کاهش قابل توجه اثربخشی، کارایی را افزایش دهد و آن را به یک انتخاب کاملاً محبوب تبدیل کند.
کرنلهای 1*1:
در نهایت، از آنجاییکه pointwise convolution از این مفهوم کرنل 1*1 استفاده میکنند، بهتر است به کاربردهای کرنل 1*1 نیز اشاره کنیم.
یک کرنل 1*1 یا بهتر است بگوییم nتا کرنل 1*1*m که در آن n تعداد کانالهای خروجی است و m تعداد کانالهای ورودی است را میتوان خارج از separable convolutionها استفاده کرد. یکی از اهداف واضح کرنل 1*1 افزایش یا کاهش عمق یک تصویر است. اگر متوجه شدید که شبکهی کانولوشن شما تعداد بسیار زیاد یا بسیار کمی کانال دارد، یک کرنل 1*1 میتواند به تعادل آن کمک کند.
با این حال، به نظر میرسد هدف اصلی کرنل 1*1 اعمال غیرخطی بودن است. بعد از هر لایهی یک شبکه عصبی، میتوانیم یک لایهی فعالسازی اعمال کنیم. لایههای فعالسازی چه ReLU، PreLU، Softmax یا هر لایهی دیگر برخلاف لایههای کانولوشن، غیرخطی هستند. «ترکیب خطی از خطوط همچنان خط است». لایههای غیرخطی، امکانات مدل را گسترش میدهند، همانطور که یک شبکهی «عمیق» از یک شبکهی «گسترده» بهتر عمل میکند. به منظور افزایش تعداد لایههای غیرخطی بدون افزایش قابل توجه تعداد پارامترها و محاسبات، میتوانیم یک کرنل 1*1 اعمال کنیم و پس از آن یک لایه فعالسازی اضافه کنیم. این روند، یک لایه در امتداد عمق به شبکه اضافه میکند.
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دیدگاه ها