
معرفی شبکه Region-based CNN (R-CNN)
- دسته:اخبار علمی
- هما کاشفی
زمانی که مقالهی R-CNN از UC Berkely در سال 2014 منتشر شد، هیچ کس نمیتوانست تأثیر آن را در سالهای بعدی پیش بینی کند. در این مقاله، نویسندگان یک مفهوم پایه را برای تمام شبکههای تشخیص شی مدرن معرفی کردهاند: ترکیب Region Proposalها با CNN. آنها شبکهی خود را R-CNN نامیدند. در این پست، این شبکه را به اختصار معرفی میکنیم.
ابتدا باید مقالهی RCNN با عنوان “Rich feature hierarchies for accurate object detection and semantic segmentation” را درک کنید. برای درک این مقاله، لازم است شهودی که پشت مفاهیم آن وجود دارد را درک کنید. به یاد داشته باشید، دانستن اصول اولیه و پایه بسیار مهمتر از «نیمه دانستن» رویکردهای جدید و پیشرفته است.
سیستم R-CNN
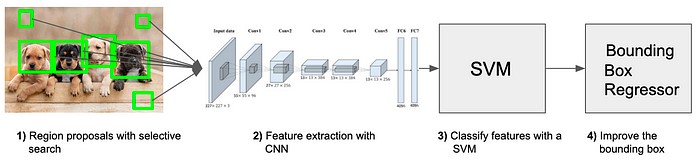
مسئلهای که سیستم R-CNN سعی در حل آن دارد، مکانیابی اشیا در تصویر است (Object Detection). برای حل این موضوع چه باید کرد؟ میتوانید با رویکردهای پنجرهی لغزان (Sliding Window) آغاز کنید. برای استفاده از این روش، کار اصلی که میکنید آن است که کل تصویر را با مستطیلهای با سایزهای مختلف مرور میکنید و تصاویر کوچکتر را با دقت بیشتری بررسی میکنید. مشکل آن است که تعداد زیادی تصویر کوچکتر برای مشاهده خواهید داشت. اما ما خوش شانس بودهایم و افراد باهوش دیگر، الگوریتمهایی برای انتخاب هوشمندانهی region proposalها ارائه کردهاند. برای سادهسازی این مفهوم:
Region Proposal
الگوریتمهای مختلفی برای Region Proposal وجود دارند که میتوانیم از بین آنها انتخاب کنیم. آنها الگوریتمهای «عادی» هستند و مجبور نیستیم آنها را آموزش دهیم و یا مرحلهی اضافی دیگری وجود ندارد. در این مقاله، نویسندگان از روش جستجوی انتخابی (Selective Search) برای تولید Region Proposalها استفاده کردهاند. به یاد داشته باشید:
R-CNN، الگوریتم خاصی برای تولید Region Proposal ندارد.
میتوانید هر الگوریتمی که دوست دارید را انتخاب کنید، البته در صورتی که کارایی مناسبی داشته باشد.
این الگوریتم نزدیک به 2000 ناحیهی مختلف ایجاد میکند که باید آنها را بررسی کنیم. این عدد کمی بزرگ به نظر میرسد اما در مقایسه با رویکرد پنجرهی لغزان به مراتب سبکتر و کم هزینهتر است.
CNN
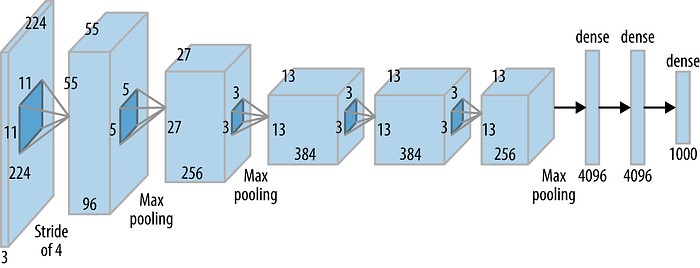
در مرحلهی بعد، هر Region Proposal را به طور جداگانه در نظر میگیریم و با استفاده از شبکه عصبی کانولوشنی(CNN)، یک بردار ویژگی ایجاد خواهیم کرد که این تصویر را در ابعاد کوچکتری نشان میدهد.
نویسندگان مقاله از AlexNet به عنوان استخراج کننده ویژگی استفاده کردند. فراموش نکنید که سال 2014 است و AlexNet هنوز به نوعی پیشرفته است (چقدر زمان، همه چیز را تغییر داده است! ….)
سوالی که باید به آن پاسخ دهیم:
اگر فقط از AlexNet به عنوان استخراج کنندهی ویژگی استفاده میکنید، چطور باید آن را آموزش دهیم؟
خوب، این یک مشکل اساسی در سیستم R-CNN است. شما نمیتوانید کل سیستم را با یک حرکت، آموزش دهید (این مشکل بعدها توسط شبکه Fast R-CNN حل شد). در عوض، شما باید هر قسمت را به طور مستقل آموزش دهید. این بدان معناست که AlexNet قبلاً با یک تسک طبقهبندی آموزش دیده است. بعد از آموزش، نویسندگان مقالهی R-CNN، آخرین لایهی Softmax را حذف کردهاند. اکنون آخرین لایه، یک لایهی 4096 بعدی تماماً متصل است. این بدان معناست که ویژگیهای ما 4096 بعدی هستند.
نکتهی مهم دیگری که باید در نظر داشت این است که ورودی AlexNet همیشه یکسان است (227*227*3). با این حال Region Proposalها اشکال متفاوتی دارند. بسیاری از آنها کوچکتر یا بزرگتر از سایز موردنیاز هستند. بنابراین ما باید اندازهی هر Region Proposal را تغییر دهیم.
به طور خلاصه:
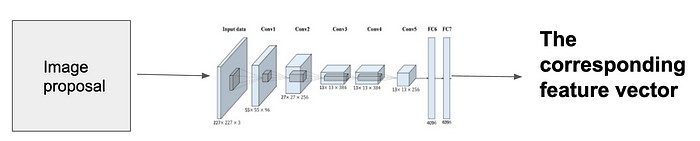
SVM
ما بردارهای ویژگی را از image proposalها ایجاد کردهایم. حال باید آن بردارهای ویژگی را کلاسبندی کنیم. ما میخواهیم تشخیص دهیم که آن بردارهای ویژگی هر یک متعلق به چه کلاسی هستند. برای این منظور از یک کلاسیفایر SVM استفاده میکنیم. برای هر کلاس شی، یک SVM در نظر میگیریم و از همهی آنها استفاده میکنیم. این بدان معنی است که برای یک بردار ویژگی، n ویژگی داریم که n تعداد اشیا مختلفی است که قرار است آنها را شناسایی کنیم. خروجی نیز یک confidence Score است. معنی این است که چقدر مطمئن هستیم که این بردار ویژگی خاص نشانگر کلاس به خصوص است.
شاید برایتان سوال باشد که چگونه SVMهای مختلف را آموزش میدهیم. خوب ما آنها را روی بردارهای ویژگی ایجاد شده توسط AlexNet آموزش میدهیم. این بدان معناست که باید منتظر بمانیم تا CNN را به طور کامل آموزش دهیم تا بتوانیم SVM را آموزش دهیم. آموزش این دو قابل موازی سازی نیست.
به طور خلاصه:
ما Image Proposalهای مختلفی را از یک تصویر ایجاد کردیم.
سپس با استفاده از شبکه CNN، یک بردار ویژگی از آن پیشنهادات ایجاد کردیم.
در پایان هر بردار ویژگی را با SVM برای هر کلاس شی، کلاسبندی کردیم.
خروجی:
حال Image Proposalهایی داریم که برای هر کلاس شی، کلاسبندی شدهاند. حال چگونه همهی آنها را به تصویر برگردانیم؟ از مفهومی به نام non-maximum suppression استفاده میکنیم. این کلمهی فانتزی، مفهوم زیر را بیان میکند:
اگر ناحیهای (Image Proposal) مقدار همپوشانی Intersection-over-union (IoU) با ناحیهی انتخابی با امتیاز بالاتر داشته باشد، آن را رد میکنیم.
اگر بین نواحی، همپوشانی وجود داشته باشد، هر ناحیه را با ناحیهی با امتیاز بالاتر (محاسبه شده توسط SVM) ترکیب میکنیم. این مرحله را برای هر کلاس به طور مستقل انجام میدهیم. پس از پایان این مرحله، فقط نواحی با امتیاز بالاتر از 0.5 را نگه میداریم.
نتیجهگیری
کشف مهم این مقاله آن بود که بسیار موثر است که شبکه CNN روی یک تسک با میزان زیادی داده آموزش ببیند (برای مثال کلاسبندی تصویر) و سپس شبکه برای تسک اصلی که Object Detection بود تنظیم شود.
درک مفاهیم ارائه شده در این مقاله برای درک کامل رویکردهای مدرنتر در حوزهی Object Detection ضروری است.
در دورهی جامع و پروژه محور کاربرد شبکههای عمیق در بینایی ماشین، این شبکه به طور کامل توضیح داده شده و پروژههای مربوط به آن پیادهسازی شدهاند.
دوره های مرتبط

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین

دیدگاه ها