پیاده سازی یک autoencoder ساده در کراس
- دسته:اخبار علمی
- هما کاشفی
می خواهیم به نحوه ی پیاده سازی autoencoderها در کراس نگاهی بیندازیم، معماری شبکه عصبی که سعی می کند بازنمایی فشرده ای از داده ی ورودی به دست دهد.
به زبان ساده، یک autoencoder (یا خودرمزنگار)، با سعی بر کپی کردن ورودی به خروجی، بازنمایی یا کدی از داده ی ورودی را خواهد آموخت. اما کاربرد autoencoderها به این سادگی نیست که ورودی روی خروجی کپی شود، مهمترین کاربرد آن یادگیری ساختار نهان (latent space) است که خروجی از روی آن ساخته میشود.
روند کلی کار autoencoderها چگونه است؟
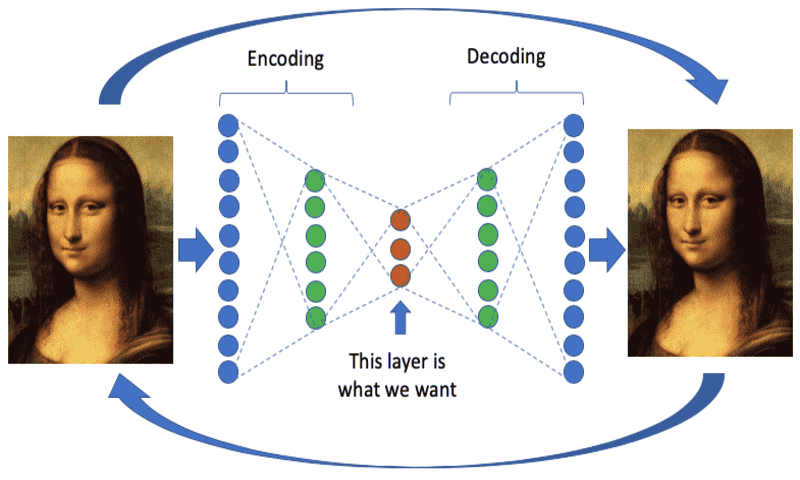
یک autoencoder ابتدا توزیع ورودی را به یک تنسور با ابعاد پایین کدگذاری (انکد) میکند و اغلب فرم بردار را به خود میگیرد. این روند باعث میشود که ساختار نهان دادهی ورودی تقریب زده شود و آن را latent Representation یا Code/vector می نامند. این قسمت، بخش encoding را تشکیل میدهد.
سپس latent vector توسط بخش decoder کدگشایی خواهد شد تا دادهی ورودی اصلی را بازیابی کند.
در نتیجه latent vector یک بازنمایی فشرده با ابعاد پایین از توزیع دادهی ورودی به دست میدهد. عدم شباهت بین ورودی و خروجی را میتوان با یک loss function تقریب زد.
چرا از autoencoderها استفاده میکنیم؟
این شبکهها یک ابزار کلیدی مهم در درک مفاهیم پیشرفته یادگیری عمیق هستند؛ زیرا این شبکهها یک بازنمایی ابعاد پایین از دادهی ورودی به ما میدهند. همچنین میتوان از این شبکهها استفاده کرد و عملیات ساختاری روی دادهی اصلی ایجاد کرد. عملیاتی چون نویززدایی از تصویر، رنگ آمیزی تصاویر یا سگمنتیشین یا تولید تصاویر جدید برای آموزش بهتر مدل.
ساختار Autoencoder
برای پیاده سازی autoencoder ابتدا باید ساختار آن را به خوبی بشناسیم و بدانیم که از دو بخش جداگانه تشکیل شده است.
1-Encoder
این بخش، دادهی ورودی x را به یک latent vector با ابعاد پایین نگاشت میکند. از آنجاییکه latent vector ابعاد پایینی نسبت به ورودی دارد، encoder مجبور میشود که تنها مهمترین ویژگیهای دادهی ورودی را یاد بگیرد. برای مثال در مورد ارقام MNIST، ممکن است مهم ترین ویژگیها ضخامت ارقام، زاویه ی نوشتن یا سبک نوشتن باشد. اینها مهمترین اطلاعات موردنیاز برای نمایش ارقام صفر تا نه هستند.
2-Decoder
این بخش سعی میکند که ورودی را از latent vector بازیابی کند. اگرچه latent vector ابعاد پایینی دارد اما سایز کافی و مناسبی دارد و به decoder این امکان را میدهد که دادهی ورودی را بازیابی کند. هدف decoder آن است که x~ را تا حد ممکن به x نزدیک سازد. در حالت کلی هر دوی encoder و decoder توابع غیرخطی هستند. بعد z معیاری از ویژگیهای برجستهی ورودی است. ابعاد latent space معمولاً بسیار کوچکتر از ابعاد ورودی است و برای آن است که این بخش محدود شود تا تنها مهمترین و برجستهترین ویژگی های داده ی ورودی را یاد بگیرد.
همچنین به یک Loss function مناسب نیاز است که بررسی کند x ورودی با x ساخته شدهی خروجی چقدر متفاوت است. برای مثال، این تابع هزینه میتواند MSE (mean square error) باشد:
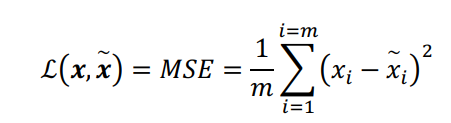
مشابه سایر شبکههای عصبی، autoencoder تلاش میکند که این تابع خطا یا loss را تا حد ممکن در حین آموزش کوچک کند. در شکل زیر یک autoencoder نشان داده شده است. encoder تابعی است که ورودی x را به یک بردار latent با ابعاد کمتر z فشرده میکند. این بردار latent نشانگر مهمترین ویژگیهای توزیع ورودی است. سپس decoder سعی میکند که ورودی اصلی را از بردار latent بازیابی کند.

حال فرض کنید میخواهیم یک شبکه autoencoder ساده برای دیتاست MNIST بسازیم. به این ترتیب x ارقام دیتاست MNIST خواهد بود که ابعادی به صورت 28*28*1=784 دارد. encoder، ورودی را به یک z با ابعاد پایین تبدیل میکند که میتواند بردار latent 16 بعدی باشد. سپس decoder سعی میکند که ورودی را از z بازیابی کند.
پیاده سازی یک autoencoder در کراس برای ارقام MNIST
برای پیاده سازی یک autoencoder ساده در کراس برای ارقام MNIST به صورت زیر عمل میکنیم:
Python
Python

دوره های مرتبط
دیدگاه ها