مدلهای مختلف Generative AI
- دسته:اخبار علمی
- هما کاشفی
اثر Generative AI بر مشاغل مختلف بسیار زیاد بوده و همچنان در حال رشد است. به همین جهت، توجه به این حوزهی پژوهشی بسیار مهم است. در این مقاله مدلهای مختلف Generative AI، نحوهی عملکرد آنها و کاربردهای عملی آنها در زمینههای مختلف را مورد بررسی قرار میدهیم.
هوش مصنوعی مولد یا Generative AI چیست؟
Generative AI به الگوریتمهای یادگیری ماشین بدون نظارت و نیمه نظارتی اشاره دارد که کامپیوترها را قادر میسازد تا از محتوای موجود مانند متن، فایلهای صوتی و ویدیویی، تصاویر و حتی کد برای تولید محتوای جدید استفاده کنند. ایدهی اصلی این حوزه آن است که محتواهای تولید شده کاملاً شبیه به محتواهای اصلی باشند.
این حوزه، کامپیوترها را قادر میسازد تا الگوهای اصلی دادههای ورودی را استخراج کنند تا مدل بتواند با استفاده از آنها محتوای جدید تولید کند. در حال حاضر، چندین مدل Generative AI پرکاربرد وجود دارد که در ادامه آنها را بررسی خواهیم کرد.
شبکههای مولد تخاصمی یا Generative Adversarial Networks: فناوریهایی هستند که میتوانند محتواهای بصری و چندرسانهای را هم از ورودیهای تصویر و هم از ورودیهای متنی ایجاد کنند.
مدلهای مبتنی بر Transformer: شامل فناوریهایی مانند مدلهای زبانی Generative Pre-Trained (GPT) هستند که میتوانند اطلاعات جمع آوری شده در اینترنت را برای خلق محتوای متنی جدید استفاده کنند.
خودرمزنگارهای متغیر یا Variational Autoencoders (VAEs) که در تسکهایی مانند تولید تصویر و تشخیص ناهنجاری مورد استفاده قرار میگیرند.
مدلهای Diffusion: که برای ایجاد تصاویر و ویدیوهای واقعی از ورودی نویز تصادفی به عملکرد قابل توجهی دست پیدا کردهاند.
برای درک ایدهی پشت Generative AI، ابتدا لازم است تمایز بین مدلسازی Generative و Discriminative را درک کنیم.
هوش مصنوعی مولد چطور کار میکند: مدلسازی Discriminative در برابر Generative
مدلسازی Discriminative برای کلاسبندی نقاط دادهی موجود استفاده میشود (برای مثال کلاسبندی تصاویر مربوط به سگ و گربه). این نوع مدلسازی بیشتر متعلق به تسکهای یادگیری ماشین نظارت شده است.
مدلسازی Generative سعی میکند ساختار دیتاست را درک کند و نمونههای مشابهی را تولید کند (برای مثال ایجاد یک تصویر واقعی از سگ یا گربه). این نوع مدلسازی بیشتر به تسکهای یادگیری ماشین بدون نظارت و نیمه نظارتی تعلق دارد.
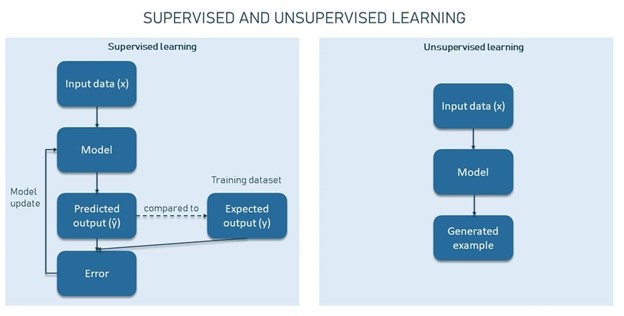
هرچقدر شبکههای عصبی بیشتر در زندگی ما نفوذ کنند، حوزههای مدلسازی Generative و Discriminative بیشتر رشد میکنند. بیایید هر یک از این دو حوزه را با جزئیات بیشتری مورد بررسی قرار دهیم.
مدلسازی Discriminative
اکثر مدلهای یادگیری ماشین برای پیش بینی استفاده میشوند. الگوریتمهای Discriminative سعی میکنند که دادههای ورودی را با توجه به مجموعهای از ویژگیها کلاسبندی کنند. و برچسب و یا کلاسی که یک نمونه داده (یا مشاهده) به آن تعلق دارد را پیش بینی کنند.
فرض کنید دادههای آموزشی در اختیار داریم که حاوی تصاویر متعددی از گربهها وسگهاست. به این ها نمونه (sample) نیز میگویند. هر نمونه دارای ویژگیهای خاصی است. ما همچنین یک شبکه عصبی در اختیار داریم که هدف آن درک نحوهی تمایز بین دو کلاس است. در طول آموزش، هر برچسب پیش بینی شده (y’) با برچسب واقعی (y) مقایسه میشود. مدل بر اساس تفاوت بین این دو مقدار به تدریج روابط بین ویژگیها و کلاسها را یاد میگیرد و نتایج خود را به هم مرتبط میکند.
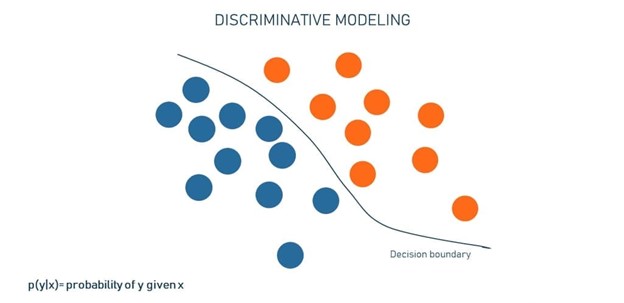
حال بیایید تفاوت بین گربه و سگ را فقط به دو ویژگی در مجموعه ویژگی X محدود کنیم (به عنوان مثال «وجود دم» و «شکل گوش»). از آنجاییکه هر ویژگی نشانگر یک بعد است، ارائهی آنها در فضای دادهی دو بعدی آسان خواهد بود. در تصویر بالا، نقاط آبی سگ و نقاط نارنجی گربه هستند. این خط، مرز تصمیمگیری را نشان میدهد یا اینکه مدل یاد میگیرد گربهها و سگها را بر اساس آن ویژگیها جدا کند. زمانی که این مدل از قبل آموزش دیده باشد، بررسی میکند که تصویر جدید در کدام مرز تصمیم قرار میگیرد. برای انجام این کار، مدل به نوعی «به یاد میآورد» این نمونهی جدید با توجه به آن چه که قبلاً دیده است چطور به نظر میرسد.
به طور خلاصه میتوان گفت، مدل Discriminative، اطلاعات مربوط به تفاوتهای تصاویر سگ و گربه را فشرده سازی میکند بدون اینکه دقیقاً بفهمد گربه یا سگ چیست.
مدلسازی Generative
الگوریتمهای Generative کاملاً برعکس عمل میکنند-به جای پیش بینی برچسب با توجه به ویژگیها، سعی میکنند که ویژگیهایی که برچسب خاصی دارند را پیش بینی کنند. الگوریتمهای Discriminative به روابط بین X, Y اهمیت میدهند؛ مدلسازی Generative به نحوهی تولید X از Y اهمیت میدهند.
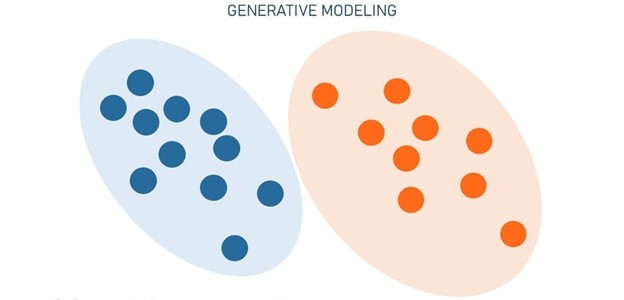
از نظر ریاضی، مدلسازی Generative به ما امکانی میدهد تا احتمال وقوع X, Y را مشخص کنیم. این مدلسازی بر یادگیری ویژگیها و روابط آنها تمرکز میکند تا ایدهی آن را بدست آورد که چه چیزی گربهها را شبیه گربه و سگها را شبیه به سگ میکند. در نتیجه چنین الگوریتمهایی نه تنها میتوانند دو حیوان را از هم تفکیک کنند، بلکه میتوانند تصاویر آنها را بازسازی یا تولید کنند.
ممکن است این سوال را بپرسید که «چرا به الگوریتمهای Discriminative نیاز داریم؟». واقعیت این است که نظارت بر آنها آسانتر بوده و قابل توضیحتر هستند- به عبارت دیگر، میتوانید درک کنید که چرا یک مدل به نتیجهی خاصی میرسد.
علاوه بر این، در بسیاری از موارد مهم نیست که دادهها چطور تولید شدهاند-ما فقط باید بدانیم که دادهها به چه دستهای تعلق دارند و این دقیقاً جایی است که برتری مدلهای Discriminative مشخص میشود. به تحلیل احساسات در نظرات ارائه شده در مورد خدمات یک هتل فکر کنید. هدف آن تشخیص مثبت یا منفی بودن یک نظر است، نه ایجاد نظرات جعلی. مدلهای Discriminative همچنان گزینهای هستند که برای تشخیص تصویر، طبقهبندی اسناد، کشف تقلب و بسیاری از کارهای روزمرهی تجاری دیگر استفاده میشوند.
الگوریتمها و مدلهای Generative AI
الگوریتمها و مدلهای مختلفی برای ایجاد محتوای جدید و واقعی از دادههای موجود توسعه یافتهاند. برخی از مدلها که هر یک مکانیزیمها و قابلیتهای متمایزی هستند، مدلهای پیشرو در زمینههایی مانند تولید تصویر، ترجمه متن و ترکیب دادهها هستند. برخی از مدلها مانند GAN اگرچه در حال حاضر کمی قدیمی هستند اما هنوز در حال استفاده هستند.
شبکههای GAN
یک شبکه مولد تخاصمی یا GAN یک چارچوب یادگیری ماشین است که دو شبکه عصبی (generator, discriminator) را در مقابل هم قرار میدهد از این رو نوعی تخاصم یا دشمنی در این شبکه وجود دارد. رقابت بین آنها یک بازی zero-sum است که در آن سود یک طرف به ضرر طرف دیگر منجر میشود.
شبکه GAN توسط Ian Goodfellow و همکارانش در دانشگاه مونترال در سال 2014 اختراع شد. آنها معماری GAN را در مقالهای با عنوان Generative Adversarial Networks توصیف کردند. از آن زمان تاکنون پژوهشها و کاربردهای عملی زیادی صورت گرفته است. تا زمان موفقیت Transformerها و مدلهای مبتنی بر Diffusion، مدلهای GAN محبوبترین الگوریتمهای هوش مصنوعی بودند.
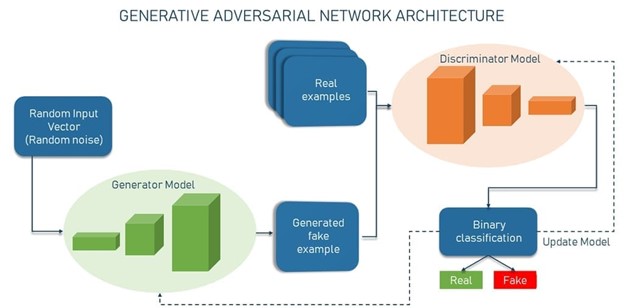
شبکههای GAN در معماری خود دو مدل یادگیری عمیق دارند:
Generator: شبکه عصبی که وظیفهی آن ایجاد ورودی جعلی یا نمونههای جعلی از یک بردار تصادفی است (لیستی از متغیرهای ریاضی با مقادیر ناشناخته).
Discriminator: شبکه عصبی که وظیفهی آن گرفتن یک نمونهی مشخص و تصمیم گیری در مورد جعلی بودن یا واقعی بودن آن است.
شبکهی discriminator یک کلاسبند باینری است که احتمالات را برمیگرداند-عددی بین 0 و 1. هرچقدر نتیجه به صفر نزدیکتر باشد، احتمال جعلی بودن خروجی بیشتر میشود. برعکس، اعداد نزدیک به یک، نشاندهندهی احتمال واقعی بودن پیش بینی هستند.
هر دو شبکهی generator, discriminator به عنوان شبکههای CNN (شبکههای عصبی کانولوشنی) پیاده سازی میشوند؛ به خصوص زمانی که هدف کار با تصاویر است.
بنابراین ماهیت خصمانهی GANها در سناریوی تئوری بازی نهفته است که در آن شبکه generator باید با حریف رقابت کند. در این سناریو همیشه یک برنده و یک بازنده وجود دارد. هر شبکهای که شکست بخورد به روز میشود در حالیکه رقیب آن بدون تغییر باقی میماند. شبکههای GAN زمانی موفق میشوند که generator یک نمونهی جعلی ایجاد کند و آنقدر قانع کننده باشد که بتواند انسان را فریب دهد. اما بازی به همین جا ختم نمیشود. زمان آن رسیده که discriminator به روز شود و بهتر کار کند.
مدلهای مبتنی بر Transformer
معماری Transformer که اولین بار در مقالهی 2017 گوگل معرفی شد یک فریم ورک یادگیری ماشین است که برای تسکهای پردازش زبان طبیعی NLP بسیار موثر است. این مدل میآموزد که الگوها را در دادههای توالی مانند متن نوشتاری یا زبان گفتاری پیدا کند. مدل بر اساس زمینه میتواند عنصر بعدی مجموعه، برای مثال کلمهی بعدی در یک جمله را پیش بینی کند. این مدل برای ترجمه و تولید متن عالی است.
برخی از شناخته شدهترین مدلهای مبتنی بر ترانسفورمر GPT-4 متعلق به OpenAI و Claude متعلق به Anthropic هستند.
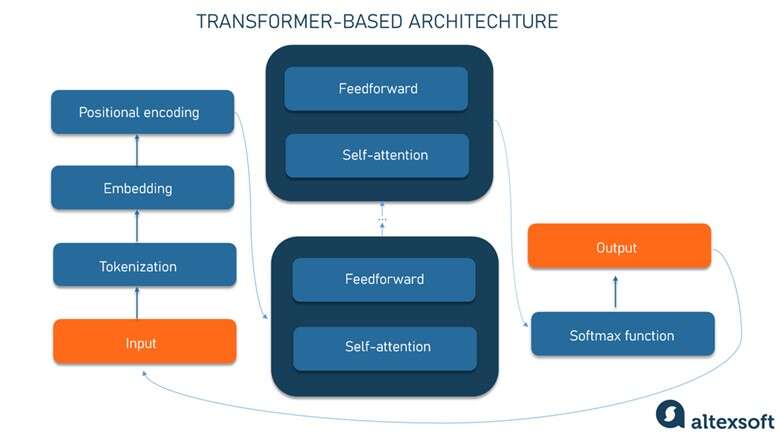
بیایید نگاهی گام به گام به نحوهی عملکرد یک مدل مبتنی بر ترانسفورمر بیندازیم.
Tokenization: ورودی (یک عبارت) به توکنها تجزیه میشود (کلمات یا زیرکلماتی مانند unbeliev از unbelievable).
Embedding: توکنهای ورودی به بردارهای عددی به نام embedding تبدیل میشوند. هر توکن با برداری منحصر به فرد (مجموعهای از اعداد با مقادیر واقعی) نشان داده میشود. یک بردار نشانگر ویژگیهای معنایی یک کلمه است و کلمات مشابه، بردارهای مشابه و نزدیک به هم دارند. برای مثال کلمهی Crown به معنای تاج ممکن است با بردار [3, 103, 35] نشان داده شود در حالیکه apple به معنای سیب با [6,7,17] نشان داده شود و pear به معنای گلابی با [6.5, 6, 18] نشان داده میشود. البته این بردارها کاملاً گویا هستند اما بردارهای واقعی، ابعاد بسیار بیشتری دارند.
Positional Encoding: برای درک متن، ترتیب کلمات در یک جمله به اندازهی خود کلمات اهمیت دارد. بنابراین در این مرحله، اطلاعات مربوط به موقعیت هر توکن در جمله در قالب یک بردار دیگر اضافه میشود و در embedding ورودی خلاصه شده است. نتیجه یک برداری است که معنای اولیه کلمه و موقعیت آن در جمله را منعکس میکند.
سپس این ورودی به شبکه عصبی transformer داده میشود که از دو بلوک تشکیل شده است.
مکانیزیم Self-Attention، روابط متنی بین توکنها را محاسبه میکند. برای این منظور اهمیت هر عنصر را در سری مشخص میکند. همچنین مشخص میکند که روابط بین آنها چقدر قوی است. از نظر ریاضیاتی، روابط بین کلمات در یک عبارت مانند فواصل و زوایای بین بردارها در یک فضای برداری چندبعدی است. این مکانیزیم میتواند راههای ظریفی که ممکن است از طریق آنها عناصر دادهای دور در یک سری بر یکدیگر اثر بگذارند را مشخص کند.
برای مثال، در جملات «آب را از پارچ در لیوان ریختم تا پر شد و آب را از پارچ به لیوان ریختم تا خالی شد»، مکانیزیم self-attention میتواند معنای آن را تشخیص دهد: در مورد اول، ضمیر به لیوان اشاره دارد و در دومی به پارچ اشاره دارد.
شبکهی Feedforward با استفاده از دانش مربوط به کلمات که از دادههای آموزشی آموخته است، نمایش نشانهها را اصلاح میکند.
مراحل self-attention و feedforward چندین بار از طریق لایههای پشتهای تکرار میشوند. برای مدل امکانی را فراهم میآورند تا الگوهای پیچیدهتر را قبل از تولید خروجی نهایی ثبت کنند. در پایان تابع softmax برای محاسبه احتمال خروجیهای مختلف و انتخاب محتملترین گزینه استفاده میشود. سپس خروجی تولید شده به ورودی اضافه میشود و کل فرآیند تکرار میشود.
مدلهای Diffusion
یک مدل Diffusion مدل مولدی است که با تقلید از دادههایی که روی آنها آموزش دیده است، دادههای جدیدی مانند تصاویر یا صدا ایجاد میکند.

مدل Diffusion را به عنوان یک هنرمند مرمتگر در نظر بگیرید که نقاشیهای استادان قدیمی را مطالعه کرده و اکنون میتواند بومهایی را به همان سبک آنها نقاشی کند. مدل Diffusion تقریباً همین کار را در سه مرحله اصلی انجام میدهد.
انتشار یا diffusion مستقیم به تصویر اصلی، نویز اضافه میکند تا زمانیکه نتیجه، مجموعهای بی نظم از پیکسلها باشد. این فرآیند شبیه به انتشار فیزیکی است و نام این مدل هم از این فرآیند فیزیکی گرفته شده است.
اگر به قیاس خود از هنرمند-مرمتگر بازگردیم، انتشار مستقیم توسط زمان مدیریت میشود و نقاشی را با شبکهای از ترک، غبار و چربی پوشش میدهد. گاهی اوقات، روی نقاشی دوباره کار میشود و جزئیات خاصی اضافه شده و یا جزئیات دیگری حذف میشوند.
مرحلهی یادگیری مانند مطالعهی یک نقاشی برای درک مقصود اصلی استاد قدیمی است. مدل به دقت تحلیل میکند که نویز اضافه شده چگونه دادهها را تغییر میدهد. مسیر تبدیل از تصویر اصلی تا نسخهی بی نظم آن را به دقت ردیابی میکند. و یاد میگیرد که در هر مرحله چگونه باید بین دادههای اصلی و تحریف شده، تمایز قائل شود. این درک به مدل امکانی میدهد تا بتواند به طور موثر، روند را معکوس کند.
پس از یادگیری، این مدل میتواند دادههای تحریف شده را از طریق فرآیند به نام انتشار معکوس، بازسازی کند. از یک نمونهی نویز شروع میکند و تاریها را گام به گام از بین میبرد. به همان روشی که هنرمند از شر آلایندهها و پس از آن لایهبندی رنگ خلاص میشود. در نتیجه دادههای جدیدی که به دادهی اصلی نزدیک است تولید میشود. مثلاً عکسی از یک سگ اما دقیقاً همان سگی نیست که در تصویر اصلی وجود دارد.
این تکنیک، مدلهای Diffusion را قادر میسازد تا تصاویر، صداها و انواع دادههای واقعی را تولید کنند. دو ابزار DALL-E و Midjourney دو ابزار معروف تولید تصویر هستند که بر اساس مدل Diffusion کار میکنند.
Variational Autoencoders (VAEs)
مدلهای مبتنی بر VAE اولین بار در سال 2013 توسط Diederik P.Kingma و Max Welling معرفی شدند و از آن زمان به نوع محبوبی از مدلهای مولد تبدیل شدهاند.
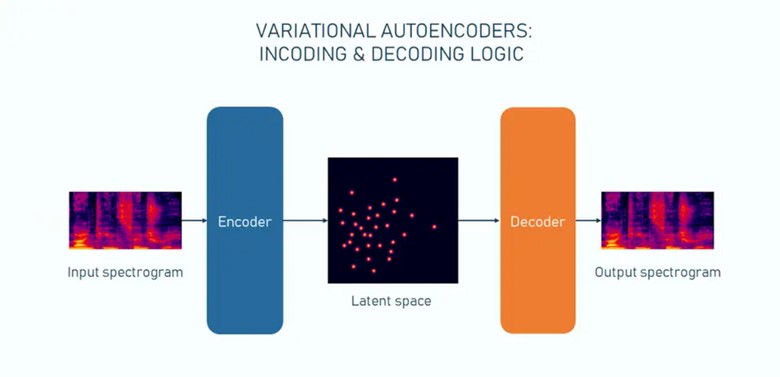
یک مدل VAE در واقع شبکه عصبی بدون نظارت است که از دو بخش تشکیل شده است: یک encoder و یک decoder. در طول مرحلهی آموزش، encoder یا رمزگذار یاد میگیرد که دادههای ورودی را در یک بازنمایی ساده شده (به اصطلاح فضای پنهان یا latent space که ابعاد کمتری نسبت به دادهی اصلی دارد) فشرده سازی کند. به این ترتیب تنها ویژگیهای اساسی ورودی اولیه را ثبت کند. هر نقطه داده با یک مقدار منحصر به فرد نمایش داده نمیشود بلکه با توزیع احتمالی مقادیر نشان داده میشود. این تصادفی بودن همان چیزی است که به autoencoder، ویژگی «متغیر بودن یا variational» را میبخشد.
بازنمایی پنهان یا latent space را به عنوان DNA یک موجود زنده در نظر بگیرید. DNA، دستورات اصلی موردنیاز برای ساخت و نگهداری یک موجود زنده را دارد. به طور مشابه، بازنماییهای پنهان حاوی اطلاعات اساسی از دادهها هستند که به مدل امکانی میدهند تا اطلاعات اصلی را از این بخش کدگذاری شده، بازسازی کند. اما اگر فقط کمی مولکول DNA را تغییر دهید، ارگانسیم کاملاً متفاوتی بدست خواهید آورد. به عنوان مثال آیا میدانستید که DNA انسان و شامپانزه تا حدود 98-99 درصد یکسان است؟
یک decoder یا رمزگشا، بازنمایی پنهان را به عنوان ورودی میگیرد و فرآیند را معکوس میکند. اما ورودی دقیق را بازسازی نمیکند؛ در عوض، چیزی شبیه به نمونههای معمولی از مجموعه داده تولید میکند. مدلهای VAE در تسکهایی مانند تولید تصویر و صدا و همچنین حذف نویز تصویر به عملکرد خوبی دست یافتهاند.
انواع کاربردهای Generative AI همراه با مثال و موارد استفاده
حوزهی Generative AI کاربردهای عملی فراوانی در حوزههای مختلف مانند بینایی ماشین دارد که در آن میتواند تکنیک Data augmentation را بهبود بخشد. پتانسیل مدل مولد واقعاً نامحدود است. در ادامه چند مورد از کاربردهای برجستهی این حوزه را خواهید دید که در حال حاضر نتایج شگفت انگیزی ارائه کردهاند.
تولید تصویر
برجستهترین مورد استفاده Generative AI، ایجاد تصاویر جعلی است که شبیه به تصاویر واقعی هستند. برای مثال در سال 2017، Tero Karras دانشمند برجسته در NVIDIA مقالهای با نام “Progressive Growing of GANs for Improved Quality, Stability and Variation» منتشر کرد.

در این مقاله، تولید تصاویر واقعی از چهرههای انسان نشان داده شد.
ترجمهی تصویر به تصویر
همانطور که از نام این حوزه پیداست، Generative AI یک نوع تصویر را به نوعی دیگر تبدیل میکند. این مجموعهای از انواع ترجمه تصویر به تصویر است.
انتقال سبک (style transfer): این تسک شامل استخراج سبک از یک نقاشی معروف و اعمال آن بر روی تصویر دیگر است. برای مثال می توانیم یک عکس واقعی که در شهر کلن آلمان گرفتهایم را به نقاشی با سبک Van Gogh تبدیل کنیم.

تبدیل اسکیس به تصاویر واقعی: در اینجا کاربر با یک طراحی پراکنده و دسته بندی شی موردنظر شروع میکند و سپس شبکه مولد، تکمیلهای قابل قبول خود را توصیه میکند و یک تصویر ترکیبی مربوط را به عنوان خروجی ارائه میدهد.

ترجمه متن به تصویر
این رویکرد، تصاویر مختلف (واقعی، نقاشی و …) از توصیفات متنی اشیا تولید میکند. محبوبترین تولید کنندههای تصویر هوش مصنوعی DALL-E از OpenAI و Stable Diffusion هستند.
برای ساختن تصویری که در ادامه میبینید، ما به مدل Stable Diffusion، توصیفات زیر را ارائه کردیم:
«رویای زمان گذشته، نقاشی رنگ روغن، سفید آبی قرمز، آبرنگ، بوم، ماهی و حیوانات»
تصویر نتیجه، کامل نیست اما کاملاً چشمگیر است.

تولید صدا
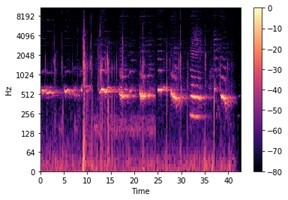
مدلهای Generative AI همچنین میتوانند دادههای صوتی را پردازش کنند. برای انجام این کار، ابتدا باید سیگنالهای صوتی را به بازنماییهای دوبعدی تصویر مانند به نام spectrogram تبدیل کنید. این به ما امکانی میدهد تا از الگوریتمهایی استفاده کنیم که به طور خاص برای کار با تصاویر طراحی شدهاند مانند CNN.
تولید ویدیو
ویدیو، مجموعهای از تصاویر متحرک است. بنابراین به طور منطقی به همان روشی که تصاویر تولید و تبدیل میشوند میتوان فیلم نیز تولید کرد. سال 2023 با پیشرفتهایی در Large Language Model (LLM) و رونق فناوریهای تولید تصویر همراه بود. سال 2024 شاهد پیشرفتهای قابل توجهی در تولید ویدیو بودیم. در ابتدای سال 2024، OpenAI یک مدل متن به ویدیوی واقعاً چشمگیر و قدرتمند به نام Sora را معرفی کرد.

Sora یک مدل مبتنی بر diffusion است که از نویز استاتیک، ویدیو تولید میکند. این مدل میتواند صحنههای پیچیده را با شخصیتهای متعدد، حرکات خاص و جزئیات دقیق سوژه و پس زمینه بسازد. مشابه مدلهای GPT، sora همچنین از معماری ترانسفورمر برای کار با پیامهای متنی استفاده میکند. علاوه بر تولید ویدیو از متن، همچنین Sora میتواند تصاویر ثابت را متحرک کند.
جنبهی تاریک Generative AI: آیا همینقدر تاریک و ترسناک است؟
تکنولوژی هر چه که باشد میتواند از آن برای اهداف خوب یا بد استفاده کرد. البته هوش مصنوعی مولد از این قاعده مستثنی نیست. در حال حاضر چندین چالش وجود دارد.
تصاویر شبه واقعی و deep fakes: فناوری deep fake که در ابتدا برای اهداف سرگرمی ایجاد شد، اما شهرت بدی پیدا کرده است. این فناوری از طریق نرم افزارهایی مانند Reface, FakeApp و DeepFaceLab به صورت عمومی در دسترس همهی کاربران قرار میگیرد.
به عنوان مثال در مارس 2022، یک ویدیوی جعلی از Volodymyr Zelensky رئیس جمهور اوکراین منتشر شد. او در این ویدیو به مردم خود میگفت که تسلیم شوند. اگرچه با چشم غیرمسلح میشد جعلی بودن ویدیو را تشخیص داد اما این ویدیو به شبکههای اجتماعی رسید و مشکلات زیادی به همراه داشت.
خطر از دست دادن کنترل: وقتی این را خطر را بیان میکنیم، منظورمان این نیست که فردا ماشینها علیه بشریت قیام میکنند و جهان را ویران میکنند. بیایید صادق باشیم ما خودمان در این کار خیلی خوب هستیم  . با این حال از آنجاییکه Generative AI میتواند خودآموزی کند، کنترل رفتار آن دشوار است. خروجی ارائه شده اغلب ممکن است از آنچه که شما انتظار دارید خیلی دور باشند.
. با این حال از آنجاییکه Generative AI میتواند خودآموزی کند، کنترل رفتار آن دشوار است. خروجی ارائه شده اغلب ممکن است از آنچه که شما انتظار دارید خیلی دور باشند.
اما همانطور که میدانیم، فناوریهای بدون چالش قادر به توسعه و رشد نخواهند بود. علاوه بر این responsible AI امکانی فراهم میکند تا از معایب نوآوریهایی مانند Generative AI اجتناب شود یا به طور کامل کاهش یابد.
به هر حال نگران نباشید، این پستی که خواندید توسط هوش مصنوعی ایجاد نشده بود
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین

دیدگاه ها