مقدمه ای بر آموزش Autoencoderها
- دسته:اخبار علمی
- هما کاشفی
هوش مصنوعی، طیف گستردهای از فناوریها و تکنیکها را در برمیگیرد که سیستمهای کامپیوتری را قادر میسازد تا مسائلی مانند فشرده سازی دادهها که در بینایی ماشین، شبکههای کامپیوتری، معماری کامپیوتر و بسیاری از زمینه های دیگر وجود دارند را حل کنند. Autoencoderها یا خودرمزنگارها، شبکههای عصبی بدون ناظر هستند که از یادگیری ماشین برای فشرده سازی داده استفاده میکنند. در این مقاله به معرفی این شبکهها میپردازیم.
خودرمزنگار یا Autoencoder چیست؟
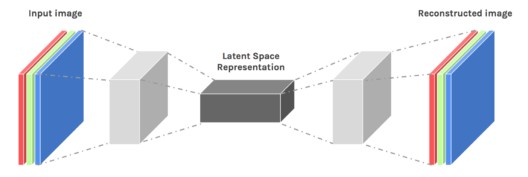
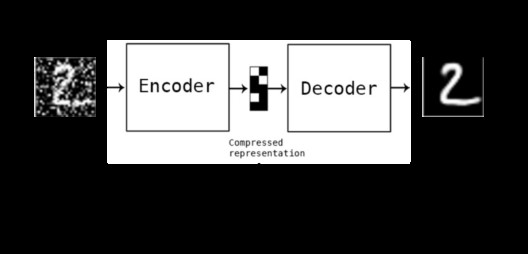
یک شبکه عصبی خودرمزنگار یک الگوریتم یادگیری ماشین بدون ناظر است که از پس انتشار خطا (backpropagation) استفاده میکند که مقادیر هدف را با ورودیها تنظیم کند. خودرمزنگارها برای کاهش اندازه ورودیها به کار میروند. اگر کسی به داده های اصلی هم نیاز داشته باشد، میتواند آن را از روی دادههای فشرده بازسازی کند.
ما یک الگوریتم یادگیری ماشین مشابه داریم مانند PCA که همین کار را انجام میدهد. بنابراین ممکن است به این مسئله فکر کنید که چرا پس به Autoencoderها نیاز داریم؟ در ادامه دلیل استفاده از Autoencoderها را متوجه میشویم.
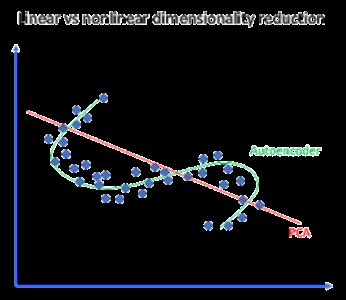
یک Autoencoder میتواند تبدیلات غیرخطی را با یک تابع فعالسازی غیرخطی و چندین لایه یاد بگیرد. نیازی به یادگیری لایه های dense نیست. این شبکه از لایههای کانولوشنی استفاده میکند تا بفهمد که کدام یک برای دادههای ویدیو، تصویر و سری زمانی بهتر است. یادگیری چندین لایه با یک autoencoder بسیار کارآمدتر از یک تبدیل عظیم با PCA است. یک Autoencoder یک بازنمایی از هر لایه به عنوان خروجی ارائه میدهد. میتواند از لایههای پیش آموزش دیده مدل دیگری استفاده کند و از یادگیری انتقالی برای encoder/decoder استفاده میکند.
حال بیایید به چند کاربرد صنعتی Autoencoder نگاهی بیندازیم
کاربردهای Autoencoderها
1)رنگ آمیزی تصویر
Autoencoderها برای تبدیل هر تصویر سیاه و سفیدی به تصویر رنگی استفاده میشوند. بسته به آنچه که در تصویر هست، میتوان تشخیص داد که رنگ هر شی چه چیزی باید باشد.

2)تغییر ویژگی
در این کاربرد، Autoencoder تنها ویژگیهای موردنیاز یک تصویر را استخراج میکند و با حذف هر گونه نویز یا وقفه غیرضروری، خروجی را تولید میکند.
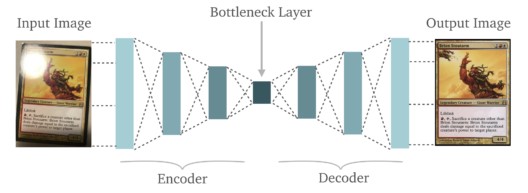
3)کاهش ابعاد
تصویر بازسازی شده مشابه ورودی است اما تنها ابعادش کاهش یافته است. این روند کمک میکند تا تصویری مشابه با مقدار پیکسل کاهش یافته تولید شود.

4)حذف نویز تصویر
ورودی مشاهده شده توسط autoencoder یک ورودی خام نیست بلکه یک نسخهی تصادفی تخریب شده از ورودی است. یک autoencoder حذف نویز به گونهای آموزش داده میشود که ورودی اصلی را از نسخهی نویزی، بازسازی کند.
5)حذف واترمارک (watermark)
همچنین این شبکه برای حذف واترمارک از تصاویر یا حذف هر شی در حین فیلمبرداری ویدیو استفاده میشود.

حال که ایدهی کلی از کاربردهای صنعتی autonencoderها داریم میخواهیم معماری آنها را یاد بگیریم.
معماری Autoencoderها
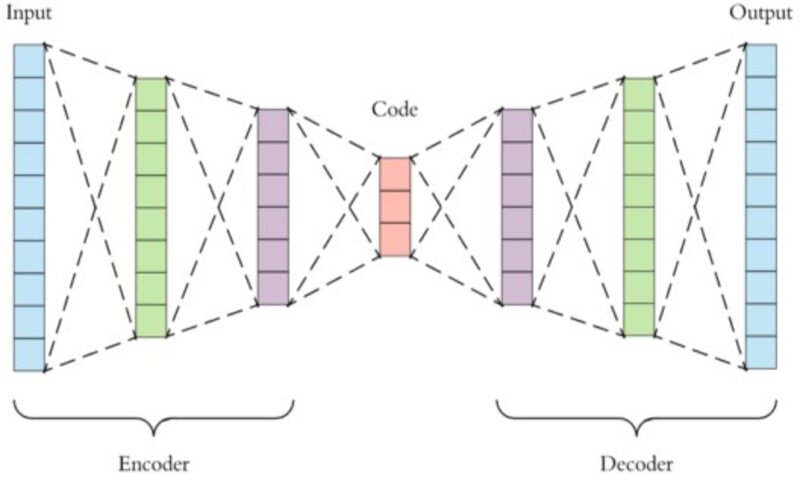
یک autoencoder از سه لایه تشکیل شده است:
Encoder (رمزگذار)
کد
Decoder (رمزگشا)
رمزگذار: این بخش از شبکه، ورودی را در یک بازنمایی فضای پنهان، فشرده میکند. لایهی رمزگذار، تصویر ورودی را به عنوان یک بازنمایی فشرده در ابعاد کاهش یافته، رمزگذاری میکند. این تصویر فشرده شده، نسخه تحریف شدهی تصویر اصلی است.
کد: این بخش از شبکه، ورودی فشرده شدهای را نشان میدهد که به رمزگشا تزریق میشود.
رمزگشا: این لایه، تصویر رمزگذاری شده را به بعد اصلی رمزگشایی میکند. تصویر رمزگشایی شده، بازسازی تصویر اصلی است و از بازنمایی فضای پنهان، بازتولید شده است.
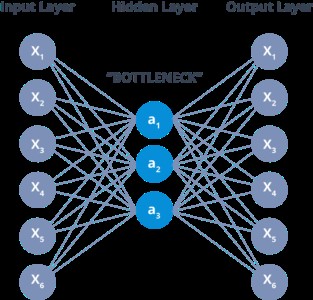
لایهی بین رمزگذار و رمزگشا که به Bottleneck نیز معروف است یک رویکرد خوب طراحی شده برای تصمیم گیری است که کدام جنبه از دادههای مشاهده شده، اطلاعات مرتبط هستند و کدام بخشها را میتوان حذف کرد. این کار با دو معیار انجام میشود:
فشردگی بازنمایی که به عنوان قابلیت فشرده سازی (compressibility) سنجیده میشود.
حال میخواهیم ویژگیهای مختلف هایپرپارامترهای موجود در آموزش autoencoderها را بررسی کنیم.
ویژگیها و هایپرپارامترها
ویژگیهای autoencoderها:
مختص به داده: شبکههای autoencoder تنها میتوانند دادههای مشابه آن چیزی که در زمان آموزش دیدهاند را فشرده کنند.
Lossy: خروجیهای فشرده شده در مقایسه با ورودیهای اصلی، کاهش مییابند.
یاد گرفته شده به طور خودکار از مثالها: بسیار ساده است که نمونههای اختصاصی از الگوریتمها را آموزش داد که روی نوع خاصی از ورودی عملکرد خوبی دارند.
هایپرپارامترهای Autoencoder
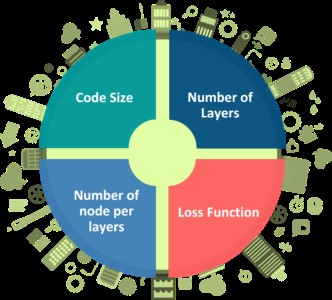
4 هایپرپارامتر وجود دارند که باید قبل از آموزش autoencoder تنظیم شوند:
سایز کد: این هایپرپارامتر نشانگر تعداد نورون ها در لایهی میانی است. اندازه کوچکتر آن باعث فشردهسازی بیشتر ورودی میشود.
تعداد لایهها: یک autoencoder را میتوان با هر تعداد لایه که بخواهیم تشکیل بدهیم.
تعداد نورونها در هر لایه: تعداد نورونها در هر لایه با لایهی بعدی رمزگذار کاهش مییابد و سپس در قسمت رمزگشا افزایش مییابد. رمزگشا از نظر ساختار لایه با رمزگذار، متقارن است.
تابع Loss: ما یا از میانگین مربعات خطا یا cross-entropy باینری باید استفاده کنیم. اگر مقادیر ورودی در محدودهی [0,1] باشند ما معمولاً از cross-entropy استفاده میکنیم و در غیر این صورت از میانگین مربعات خطا استفاده میکنیم.
انواع Autoencoderها
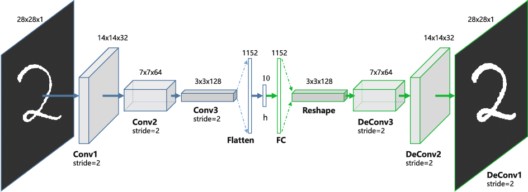
1) Convolution Autoencoderها
شبکههای autoencoder در فرمول اولیهی خود این واقعیت را در نظر نمیگیرند که یک سیگنال را میتوان به عنوان مجموع سیگنالهای دیگر دید. Convolutional autoencoderها از عملگر کانولوشن استفاده میکنند تا از این مشاهدات بهره ببرند. آنها یاد میگیرند که ورودی را در مجموعهای از سیگنالهای ساده رمزگذاری کنند و سعی میکنند ورودی را از آنها بازسازی کنند و هندسه یا بازتاب تصویر را تغییر دهند.
کاربردهای مدل کانولوشنی این شبکه عبارتند از:
-بازسازی تصویر
-رنگ آمیز تصویر
-خوشه بندی فضای پنهان
-تولید تصاویر با رزولوشن بالاتر
2)Autoencoderهای پراکنده
Autoencoderهای پراکنده، روشی جایگزین ارائه میدهند تا یک bottleneck اطلاعاتی معرفی شود بدون اینکه نیاز باشد تعداد نورونها در لایهی پنهان کاهش یابد. در عوض ما loss function را به گونهای میسازیم که فعالسازیهای درون یک لایه را جریمه کنیم.
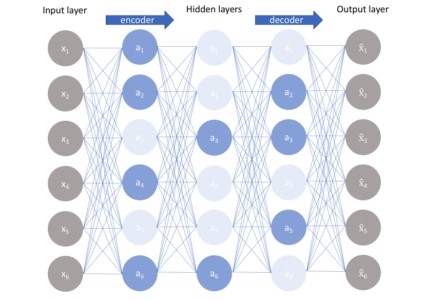
3)Autoencoderهای عمیق
اولین لایهی Autoencoder عمیق برای ویژگیهای مرتبه اول در ورودی خام استفاده میشود. لایهی دوم برای ویژگیهای مرتبه دوم مربوط به الگوهای ویژگی مرتبه اول استفاده میشود. لایههای عمیقتر Autoencoder عمیق، ویژگیهای مرتبه بالاتری را میآموزند.
یک شبکه Autoencoder عمیق از دو شبکه باور عمیق متقارن تشکیل شده است:
-چهار یا پنج لایه کم عمق نشانگر نیمهی رمزگذاری شبکه هستند.
مجموعه دوم چهار یا پنج لایه، نشانگر نیمهی رمزگشایی هستند.
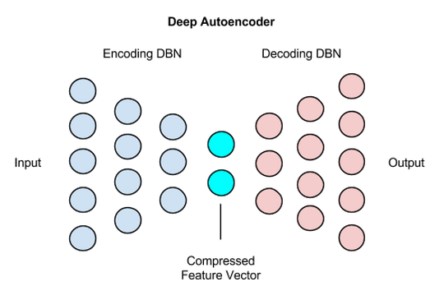
کاربردهای autoencoder عمیق عبارتند از:
-جستجوی تصویر
-فشرده سازی داده
-بازیابی اطلاعات (IR)
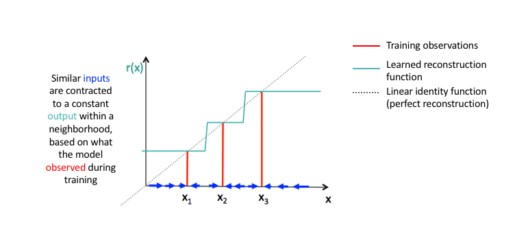
4)Autoencoderهای انقباضی
یک autoencoder انقباضی یک تکنیک یادگیری عمیق بدون ناظر است که به شبکه عصبی کمک میکند تا دادههای آموزشی بدون برچسب را رمزگذاری کند. این کار با ایجاد یک loss انجام میشود که مشتقات بزرگ فعالسازی لایهی پنهان را با توجه به نمونههای آموزشی ورودی جریمه میکند، اساساً مواردی را جریمه میکند که یک تغییر کوچک در ورودی منجر به تغییر بزرگی در فضای رمزگذاری میشود.
حال میخواهیم پیاده سازی ساده از Autoencoderها را در تنسورفلو آموزش دهیم که به منظور فشرده سازی داده انجام شده است.
فشرده سازی داده با استفاده از Autoencoderها در تنسورفلو

1-ابتدا باید کتابخانههای موردنیاز را import کنیم
Python
import numpy as np from keras.layers import Input, Dense from keras.models import Model from keras.datasets import mnist import matplotlib.pyplot as plt
2–حال باید لایههای پنهان و متغیرها را مشخص کنیم
Python
#this is the size of our encoded representations encoding_dim = 32 # 32 floats -> compression of factor 24.5, assuming the input is 784 floats #this is our input placeholder input_img = Input(shape=(784,)) # "encoded" is the encoded representation of the input encoded = Dense(encoding_dim, activation='relu')(input_img) # "decoded" is the lossy reconstruction of the input decoded = Dense(784, activation='sigmoid')(encoded) #this model maps an input to its reconstruction# autoencoder = Model(input_img, decoded) #this model maps an input to its encoded representation encoder = Model(input_img, encoded) #create a placeholder for an encoded (32-dimensional) input encoded_input = Input(shape=(encoding_dim,)) # retrieve the last layer of the autoencoder model decoder_layer = autoencoder.layers[-1] #create the decoder model decoder = Model(encoded_input, decoder_layer(encoded_input)) #configure our model to use a per-pixel binary crossentropy loss, and the Adadelta optimize autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
3-آمادهسازی دادهی ورودی (دیتاست MNIST)
Python
(x_train, _), (x_test, _) = mnist.load_data()
normalize all values between 0 and 1 and we will flatten the 28x28 images into vectors of size 78
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print x_train.shape
print x_test.shape
4-آموزش Autoencoderها با 50تا epoch
Python
(autoencoder.fit(x_train, x_train epochs=50 batch_size=256 shuffle=True validation_data=(x_test, x_test) # encode and decode some digits #note that we take them from the *test* set decoded_imgs = decoder.predict(encoded_imgs)
5-نمایش ورودیهای بازسازی شده و بازنماییهای رمزگذاری شده با استفاده از کتابخانهی Matplotlib
Python
n = 20 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
#display original
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
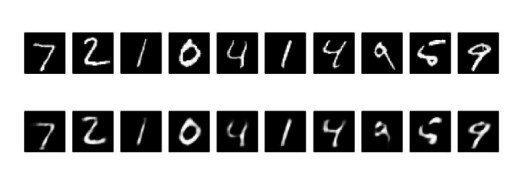
امیدواریم این مقاله برای شما مفید بوده باشد، نظرات خود را در بخش کامنت برای ما بنویسید.
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دوره جامع و پروژه محور شبکه عصبی بازگشتی RNN

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین

اصول برنامه نویسی پایتون Python

کتابخانه NumPy و matplotlib در پایتون

دیدگاه ها