
درک یادگیری انتقالی در یادگیری عمیق
- دسته:اخبار علمی
- هما کاشفی
استفاده مجدد از یک مدل از پیش آموخته شده برای یک مسئلهی جدید، یادگیری انتقالی نام دارد. مفهوم یادگیری انتقالی به طور خاص در یادگیری عمیق بسیار محبوب است زیرا این قابلیت را دارد که شبکههای عصبی عمیق را با میزان کمی داده، آموزش دهد. این حوزه به ویژه در زمینهی علم داده ارزشمند است زیرا بیشتر موقعیتهای دنیای واقعی برای آموزش مدلهای پیچیده، به میلیونها دادهی برچسب گذاری شده نیاز ندارند.
یادگیری انتقالی چیست و چطور کار میکند؟
استفادهی مجدد از یک مدل پیش آموزش دیده برای یک مسئلهی جدید به عنوان یادگیری انتقالی شناخته میشود. ماشین از دانش آموخته شده از مسئلهی قبلی استفاده میکند تا پیش بینی دقیقی برای یک تسک جدید داشته باشد. برای مثال شما میتوانید از اطلاعات حاصل مدل آموزش دیده برای تشخیص دو ماشین مختلف برای پیش بینی آن استفاده کنید که آیا یک تصویر حاوی غذا است یا خیر.
در یادگیری انتقالی، دانش یک مدل یادگیری ماشین از قبل آموزش دیده به یک مسئله ی متفاوت انتقال داده میشود. برای مثال، اگر یک کلاسیفایر ساده را برای پیش بینی آن استفاده کنید که آیا یک تصویر حاوی کوله پشتی است یا نه، میتوانید از دانش آموزش مدل برای شناسایی اشیا دیگر مانند عینک آفتابی استفاده کنید.
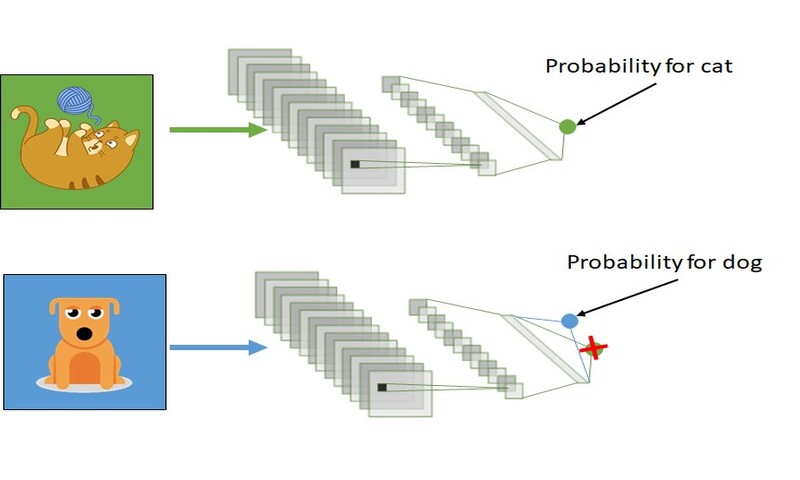
با یادگیری انتقالی اساساً سعی میکنیم که از آموختههای خود در یک تسک برای درک بهتر مفاهیم در تسک دیگر استفاده کنیم. وزنها به طور خودکار از شبکهای که «تسک A» را انجام میداده به شبکهای که «تسک B» را انجام میدهد منتقل میشوند.
به دلیل میزان انبوه توان CPU موردنیاز، یادگیری انتقالی معمولاً در تسکهای بینایی ماشین و پردازش زبان طبیعی مانند تحلیل احساسات استفاده میشود.
یادگیری انتقالی چطور کار میکند؟
در بینایی ماشین، معمولاً هدف شبکههای عصبی تشخیص لبهها در لایهی اول، شکلها در لایهی میانی و ویژگیهای خاص تسک در لایهی آخر است. لایههای اول و وسط در یادگیری انتقالی استفاده میشوند و لایههای آخر فقط بازآموزی میشوند. در هنگام آموزش از لایههای برچسب گذاری شده، استفاده میشود.
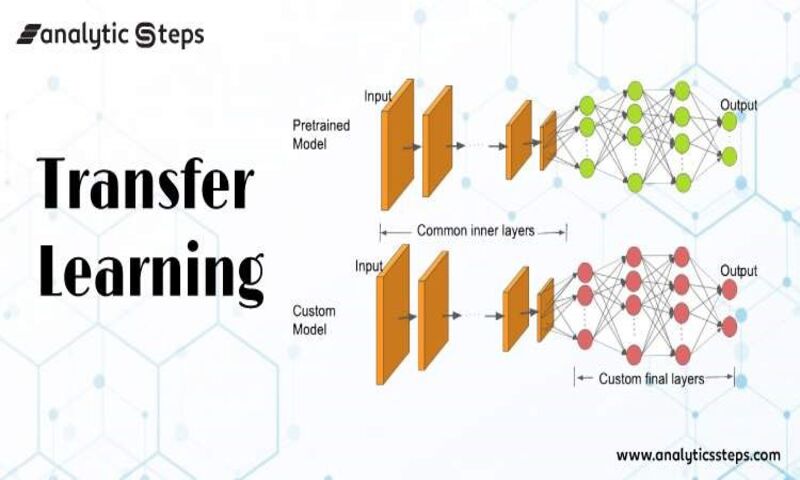
بیایید به مثالی برگردیم که برای شناسایی کوله پشتی در تصویر در نظر گرفته شده است و حال قرار است برای تشخیص عینک آفتابی استفاده شود. از آنجاییکه مدل برای تشخیص اشیا در سطوح قبلی آموزش دیده است، ما به سادگی لایههای بعدی را دوباره آموزش میدهیم تا بدانیم چه چیزی عینک آفتابی را از سایر اشیا متمایز میکند.
چرا باید از یادگیری انتقالی استفاده کرد؟
یادگیری انتقالی چندین مزیت ارائه میدهد که مهمترین آنها کاهش زمان آموزش، بهبود عملکرد شبکه عصبی (در اکثر مواقع) و عدم وجود حجم زیادی داده است.
برای آموزش یک مدل عصبی از ابتدا، معمولاً به دادهی زیادی نیاز است، اما دسترسی به آن دادهها همیشه امکان پذیر نیست، اینجا جایی است که یادگیری انتقالی مفید واقع میشود.
از آنجاییکه این مدل از قبل آموزش داده شده است، با استفاده از یادگیری انتقالی و با دادههای آموزش نسبتاً کم میتوان یک مدل یادگیری ماشین خوب تولید کرد. یادگیری انتقالی به ویژه در پردازش زبان طبیعی مفید است جایی که در اختیار داشتن مجموعه دادههای برچسب گذاری شدهی عظیم به دانش تخصصی زیادی نیاز دارد. علاوه بر این، زمان آموزش کاهش مییابد زیرا ایجاد یک شبکه عصبی عمیق از ابتدا، کاری پیچیده است و ممکن است روزها یا حتی هفتهها طول بکشد.
چه زمانی از یادگیری انتقالی استفاده کنیم؟
زمانی که دادهی برچسب گذاری شدهی کافی برای آموزش مدل خود نداریم. زمانی که یک مدل از پیش آموزش دیده وجود داشته باشد که با دادهها و تسکهای مشابه آموزش دیده است. اگر از Tensorflow برای آموزش مدل اصلی استفاده میکنید، ممکن است بخواهید آن را بازیابی کنید و چند لایه را برای تسک خود، دوباره آموزش دهید. از سوی دیگر یادگیری انتقالی تنها در صورتی کار میکند که ویژگیهای آموخته شده در تسک اول، ویژگیهای عمومی باشند به این معنی که میتوان آنها را در فعالیت دیگری نیز اعمال کرد. علاوه بر این ورودی مدل باید دقیقاً هم سایز مدلی باشد که در ابتدا آموزش دیده است. اگر چنین ورودی ندارید، باید یک مرحله برای تغییر اندازهی ورودی خود به سایر موردنیاز، اضافه کنید.
1-آموزش یک مدل استفادهی مجدد از آن
فرض کنید میخواهید تسک A را انجام دهید اما دادههای موردنیاز برای آموزش یک شبکه عصبی عمیق را در اختیار ندارید. یافتن تسک B با میزان زیادی داده یکی از روشهای انجام این کار است. برای تسک B از شبکه عصبی عمیق برای آموزش استفاده کنید و سپس از مدل بدست آمده برای حل تسک A بهره بگیرید. سپس باید تصمیم بگیرید که آیا نیاز به استفاده از کل مدل را دارید یا فقط چند لایه.
اگر ورودی در هر دو تسک یکسان است، میتوانید مدل را دوباره اعمال کنید و برای ورودی جدید خود، پیش بینی انجام دهید. از سوی دیگر، تغییر و بازآموزی لایههای خاص و لایههای خروجی، رویکرد دوم است.
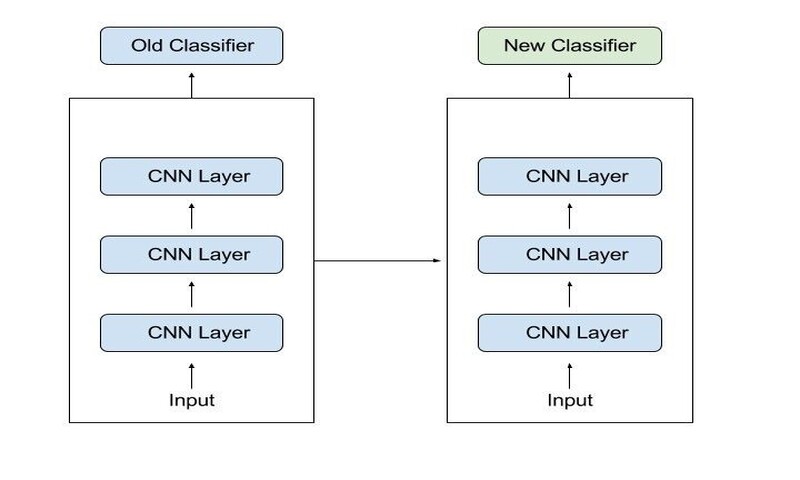
2-استفاده از یک مدل از پیش آموزش دیده
گزینهی دوم استفاده از مدلی است که قبلاً آموزش دیده است. تعداد زیادی مدل وجود دارد، بنابراین بهتر است از قبل تحقیق کنید. تعداد لایهها برای استفاده و آموزش مجدد، بسته به هر تسک تعیین میشود. Keras شامل 9 مدل از پیش آموزش دیده است که برای یادگیری انتقالی، پیش بینی و fine tuning استفاده میشود. بسیاری از موسسات پژوهشی نیز مدلهای آموزش دیده را در دسترس قرار میدهند. محبوبترین کاربرد این شکل از یادگیری انتقالی، یادگیری عمیق است.
3-استخراج ویژگیها
گزینهی دیگر استفاده از یادگیری عمیق برای شناسایی بازنمایی بهینه از مسئلهی شماست که شامل شناسایی ویژگیهای کلیدی است. این روش، یادگیری بازنمایی نامیده میشود و میتواند نتایج بسیار بهتری نسبت به بازنماییهای تولید شدهی دستی ایجاد کند.
در یادگیری ماشین، ایجاد ویژگی عمدتاً توسط محققان و متخصصان حوزه انجام میشود. خوشبختانه، یادگیری عمیق میتواند ویژگیها را به طور خودکار استخراج کند. البته این امر چیزی از اهمیت مهندسی ویژگی و دانش حوزه نمیکاهد. شما باید خودتان انتخاب کنید که کدام ویژگیها را درون شبکه قرار دهید.
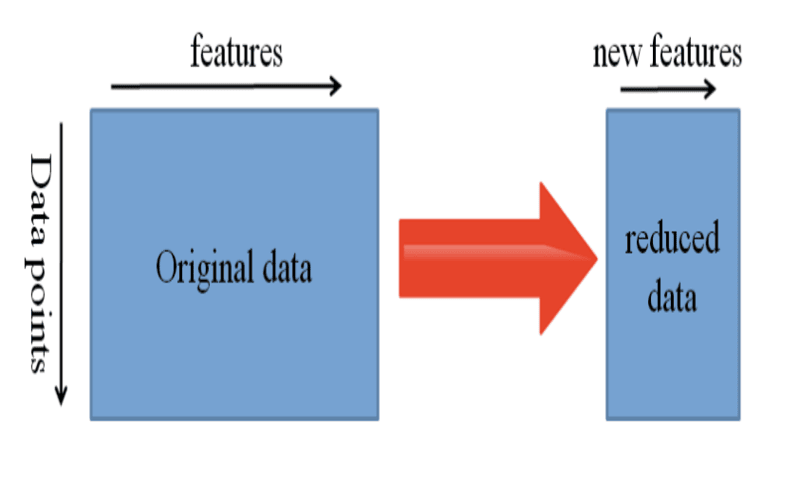
از سوی دیگر، شبکههای عصبی این قابلیت را دارند که بیاموزند کدام ویژگیها مهم و حیاتی هستند و کدامها نه. حتی برای تسکهای پیچیدهای که به تلاشهای انسانی زیادی نیاز دارند، یک الگوریتم یادگیری بازنمایی میتواند ترکیب مناسبی از ویژگیها را در مدت زمان کوتاهی بیابد.
بازنمایی آموخته شده را میتوان برای انواع چالشهای دیگر به کار برد. تنها کافی است از لایههای اولیه استفاده کنید تا بازنمایی ویژگی مناسبی بدست آورید، اما از خروجی شبکه استفاده نکنید زیرا به تسک بستگی دارد. در عوض، داده را به شبکه بدهید و از یکی از لایههای میانی، خروجی بگیرید.
سپس دادههای خام را میتوان به عنوان بازنمایی از این لایه درک کرد.
این روش معمولاً در بینایی ماشین استفاده میشود زیرا میتواند حجم دیتاست شما را کوچک کند و زمان محاسبه را کاهش دهد و آن را برای الگوریتمهای کلاسیک، مناسبتر کند.
دوره های مرتبط

پیادهسازی شبکه های عصبی با پایتورچ PyTorch

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین

دیدگاه ها