encoder
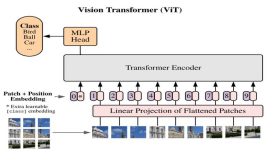
نحوهی کار Vision Transformer (ViT)
مدل ViT (Vision transformer) یک مدل شبیه به transformer است که برای انجام تسکهای پردازش بینایی طراحی شده است. در این مقاله می آموزیم که این مدل چگونه کار میکند.
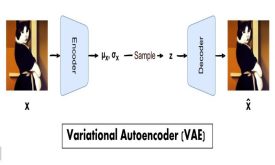
Variational Autoencoder(VAE) چیست و چه تفاوتی با Autoencoder معمولی دارد؟
در این مقاله میخواهیم ساختار Variational autoencoder (VAE) را بررسی کنیم و ببینیم چه تفاوتی با Autoencoder معمولی دارد. مدل های VAE ساده ترین نوع مدلهای مولد یا Generative modelها هستند که می توانند داده ی جدید تولید کنند.
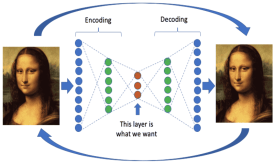
پیاده سازی یک autoencoder ساده در کراس
می خواهیم به نحوه ی پیاده سازی autoencoderها در کراس نگاهی بیندازیم، معماری شبکه عصبی که سعی می کند بازنمایی فشرده ای از داده ی ورودی به دست دهد.